Graham's Software Guide for Archaeologists
(no. 2)
G.F.McElearney
University of Sheffield
Graham's Software Guide for Archaeologists
(no. 2)
G.F.McElearney
University of Sheffield
To many they cause deep apprehension, though they are so common -- computerised data bases. Like an invasive modernist monster in a slightly post-modern world, they are everywhere from supermarket tills and libraries to international finance houses and beyond. The kind of data base system with which we engage in such a mundane act as going to the cashpoint is no doubt highly complicated, but the basic principles on which all data bases are founded are remarkably simple. In this issue we will try and make some sense of data bases: what they are and how they can be used.
A data base is simply a way of storing structured information. A classic paper-based example is a telephone directory. The information in a phone book is laid out like a big table of rows and columns. Each individual entry (i.e. phone number) forms a row in the table, and each column contains a discrete 'category' of information -- name, initials, address, number and so on.
This is the basic concept behind all computerised data bases, though data bases have their own terminology for these ideas: data are stored in tables, each row or entry in the data base is called a record, and each column or category is called a field. A data base can contain as few or as many records as needed to store your data, but each record contains the same fields.
For a slightly more archaeologically relevant context, have a look at the example below. This shows an example of a simple Sites and Monuments Records data base, containing data about the famous 'Crookesmoor Don' long barrow tradition, which is so common around Sheffield, England, where assemblage is produced.
Please note: We are using the data base application Microsoft Access® in these examples.
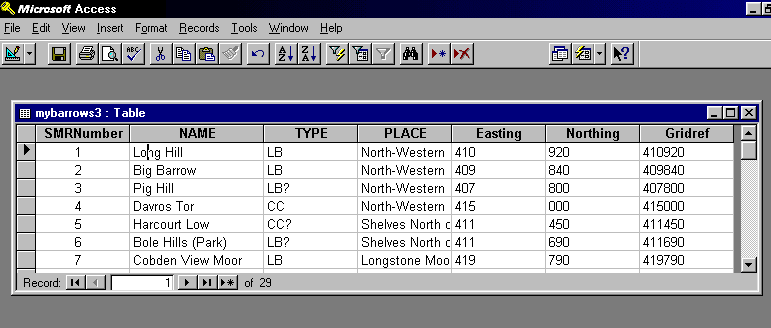
Each barrow forms a record, and each field has its own unique name which you can see at the top of each column. So far we have little more than a glorified card index stored on a computer. In real-life situations archaeologists often have to deal with masses of highly structured data sets, including bibliographies and library systems, excavation and/or experimental data, and regional and national archaeological records. Not surprisingly, data bases have been one of the longest and commonest uses of computers by archaeologists in all areas of the discipline.
Electronic data bases offer many advantages over their analogue counterparts
More importantly:
We'll take these last two points in turn.
Searching the data base
Searching data bases basically means extracting just those records needed at any particular
time. This is referred to as a 'query'. Although different data base packages work slightly
differently, it generally involves deciding
The last point is most important, since the criteria define which record(s) will be extracted
from your data base. Search criteria are normally applied on the basis of the data contained in
one or more fields. Most data base packages provide a user-friendly way of doing this. In the
example below, I have created a query in Access® to only select the Crookesmoor barrows
whose TYPE field contains 'LB'.
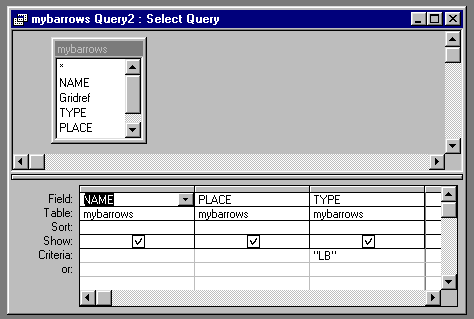
The output from this query produces something like this.
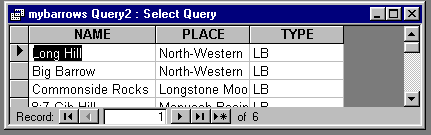
The search could be refined by combining several search criteria, for example, by searching for barrows of a certain TYPE within a certain PLACE (field names).
Most data base packages will also allow you to print your results out, as well as allowing you to design the graphical lay-out of how they should appear when printed. Printing out results is normally called creating a report.
Linking data with relational data bases
So far, in our example, we have only been looking at one table. data bases that work on one table only are described as flat-file data bases. The real power in a computerised data base is being able to work with different but related data sets or tables. We will look at a simple excavation recording system to explore this power further.
A simple excavation system
We will start by briefly defining our requirements. The importance of doing this at the outset shouldn't be underestimated. We want to store information about the contexts excavated, and we want to record any finds recovered. We would also like to be able to produce a list of finds for each context.
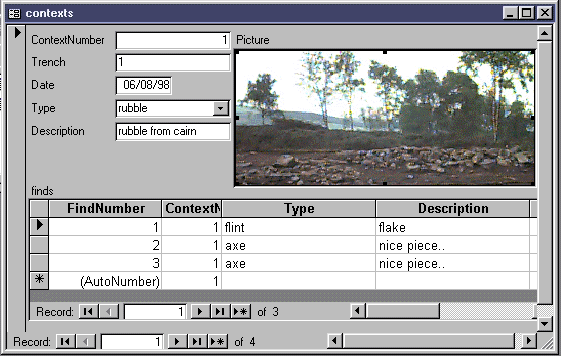
We can do this by creating a context table and a finds table. Each context and find has its own unique number, and, when stored in separate tables, they appear as seemingly independent entities. Although they can be treated in this manner, they can also be related: each find comes from a numbered context, and although each context and find are unique, one context can yield many finds. Because the context number fields match in both tables, we can join the two tables using this field to form a one to many relationship.
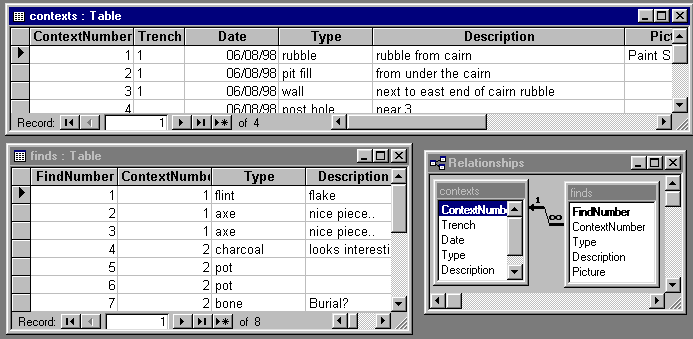
Once this is done, we can present the linked data in a form. In this case, a list of finds is produced for each context displayed, and I have added a picture for ... well, the hell of it really.
We can exploit the same relationship between the two tables in searching the data base by performing a relational query. By specifying a search criteria in the finds table, we could, for example, extract all the contexts that produced finds of a certain type.
Advanced features
The example above shows how data can be displayed using a form. Using forms makes using the data base much easier and effective. In this example, the data base user is constrained to a predetermined 'drop down' list of context types, which eliminates the possibility of typing errors. Designing forms or data entry screens used to be a very arduous task and was definitely the preserve of the experienced programmer. Modern systems like Access® make the whole task very simple, using, in this case, a series of 'Form Wizards®'. Like the Chart Wizard® mentioned in the last issue, these wizards guide you through the process step by step and provide plenty of options for designing the lay-out, adding related tables to the form, etc.
Frequently used tasks can be automated in a number of ways. Like the spreadsheets mentioned in the last issue, this can be done very simply by recording actions as macros, or by using the Macro Wizard®. Early data base packages used to be little more than programming languages dedicated to data storage and retrieval, and modern packages have inherited much of this perverse tradition. Macros and programs can be linked to buttons on forms (using the Button Wizard®, of all things!), so you can start to build quite sophisticated looking interfaces quite easily.
A few things to consider with data bases
Because the basic notion of structured data storage and retrieval is well defined, it's easier to know when to use a data base than when to use the more amorphous spreadsheet. There are still a few things to remember before you start.
I hope we have seen that data bases are simple, at least in principle, though they can be made infinitely complex in practice. The best thing to do if you think you need to use a data base, is to give it a try with some sample data and be prepared to have to try a few times until you arrive at the best data structure. After a while you should get more confident and proficient, but always remember that since data bases are computer programs, they are, of course, themselves the bastard spawn of Satan and should be treated as such.
Copyright © G.F. McElearney 1998











Copyright © assemblage 1998