
In early 2020, it was decided to take a closer look into what impact our social media accounts were having on our archives. Did what we do on social media make a difference to who sees our archives? Were our tweets heard? Were our posts seen? Above all, were people finding our archives?
The following is going to get rather technical and a little bit mathy. So if you just want the results, allow me to provide you with a TL;DR.
Page views of archives that were publicised on Facebook or Twitter were used to measure engagement per month over 2018 and 2019. To measure the impact of social media publication, three statistical models were tested. Before increasing our focus on social media, we were pulling in 15 new views to an archive whenever it was published. Once we became more active in 2019, this was raised to 45 additional views.

Back to our journey to social media discovery…
To simplify this desire to know how effective we were being, we decided to look at the past two years of data to see how traffic was being directed into our archives from social media. These two year two years had differing levels of activity on social media as in 2019, two additional staff members were hired on to help with the task. This was in contrast to 2018, where social media was not seen as much of a priority.
Two of the ADS’s social media platforms were investigated: Facebook and Twitter. Instagram was not used as it was created in 2019 and its growing impact was deemed negligible for the time being. Other social media such as LinkedIn have only recently been revitalised and thus were similarly ignored.

The posts/tweets from Facebook and Twitter were downloaded to find out which collections were publicised. While this was easy for Facebook as a direct copy of the post was available, Twitter shortens all urls, which meant these had to be reconverted back to the DOIs. These DOIs were then linked to the archive’s collection id based on in house metadata. Additionally, as we were only testing the ADS’s social media effectiveness and not the effectiveness of individual platforms, the results from both Twitter and Facebook were then pooled into one table.
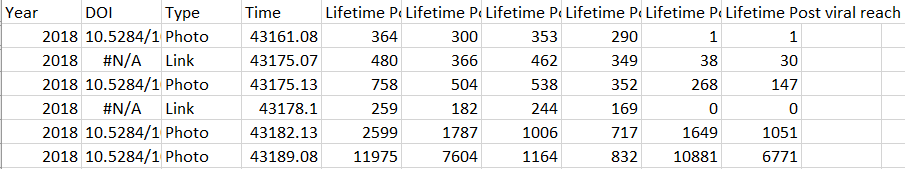


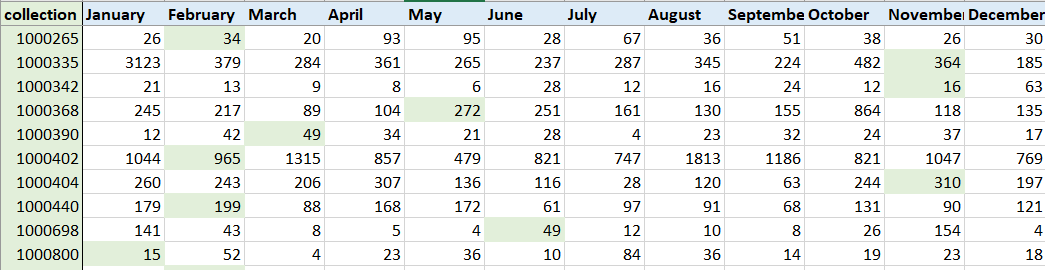
To measure the impact these sites had on redirecting traffic to our archives, we used the page visits for all collections. This was chosen for simplicity. If we had used page views or downloads, we would have had to consider both of these counts in conjunction. This would have then accounted for search interfaces (which have no downloads).
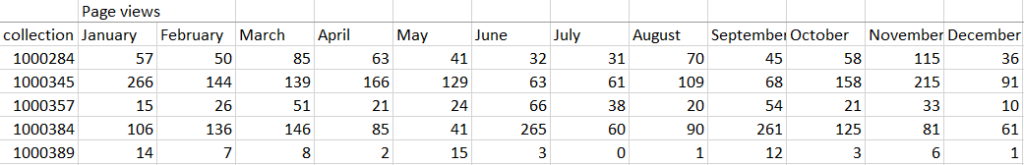
From there, the collection summaries were separated into two groups: publicised and non published. Then, the month(s) that each collection was publicised on was assigned a treatment value (1) to create a matrix. All treatment values were 1 regardless of the number of times a collection may have been published on social media during a month (archives are often published on Facebook and Twitter simultaneously).
Three models were then fitted using this information via R: independently pooled panels (IPP), independently pooled panel with fixed effect model (IPP fixed), and independently pooled panel with random effects model (IPP random). These models show if there was an effect from publicising the data, and if so, how much (R also showed additional analysis of the effectiveness of the models). The results of these models are listed in the table and explained below. Three time periods were tested using this information: 2018, 2019, and 2018-2019. By using 2018 and 2019 as separate, we control for the changes that were caused by hiring new staff. By testing 2018-2019, we established a baseline through the models tested.
| Time frame | 2018 | 2018 | 2019 | 2019 | 2018-2019 | 2018-2019 |
| Effect | Views (st.dev.)* | Treatment (st.dev.)** | Views (st.dev.)* | Treatment (st.dev.)** | Views (st.dev.)* | Treatment (st.dev.)** |
| IPP | 11.2 (± 0.6) |
9.6 (± 4.5) |
10.7 (± 0.9) |
61.5 (± 7.1) |
11 (± 0.5) |
35.7 (± 4.3) |
| IPP fixed | 9.7 (NA) |
15.2 (± 0.9) |
9.9 (NA) |
45.2 (± 5.7) |
9.9 (NA) |
29.9 (± 2.9) |
| IPP random | 9.7 (± 1.8) |
15.2 (± 0.9) |
10.2 (± 2.1) |
45.1 (± 5.5) |
10.0 (± 1.9) |
29.8 (± 2.8) |
**Additional number of views due to treatment (standard deviation)
When investigating these models, IPP shows a baseline for comparison with the other models. The ’views’ as listed in the table show the estimated number of views without promotion while the ‘treatment’ in the table shows the additional views to the archive within the month of publishing them on social media. With IPP, we see that every archive receives the same number of views every month, but then when it’s published on social media, the number of views then increases but in a highly variable manner. This, however, does not make sense with what we would expect (i.e., it wouldn’t make sense for use to get less views on an archive after publishing it on social media).
Thus, IPP fixed and IPP random were used. With these two models, we see a decrease in the standard deviation with treatment and a lower base number of views. These models show a more consistent effect for publishing archives on social media and the base number of views is more in line with what we would expect given the difference between different archives.
When you look at the models per year, the number of baseline views remains roughly the same. What significantly changes, however, is the number of additional views due to publication on social media. In 2018, there were an estimated 15 additional views while in 2019 there were 45. In 2018, social media publication was mainly limited to Friday photo and announcing new releases of archives. In 2019, however, there were additional content and themes which greatly increased the engagement on these profiles that was then reflected in increased views to archives. This increase in engagement was investigated elsewhere but was summarised in the 2018-2019 Annual Report.
So to bring a long story to a short conclusion, yes. By increasing our social media presence, we were able to increase traffic to our archives. We hope that by increasing our social media presence even more, we can continue to bring attention to the archives that we store.



