ADS blog
Between the Fictional and Real Archive
‘The book was thick and black and covered with dust.” This is the first description of archival material in A.S. Byatt’s Possession, a book that focuses…

‘The book was thick and black and covered with dust.” This is the first description of archival material in A.S. Byatt’s Possession, a book that focuses…

Data Management and Digital Preservation shouldn’t be skills only some archaeologists can access. That’s why we’re opening our vault and providing access to our training materials.…

We at the ADS and HSDS are excited to announce the launch of our new deposit system – Ingest. Ingest enables researchers, field archaeologists, heritage scientists…
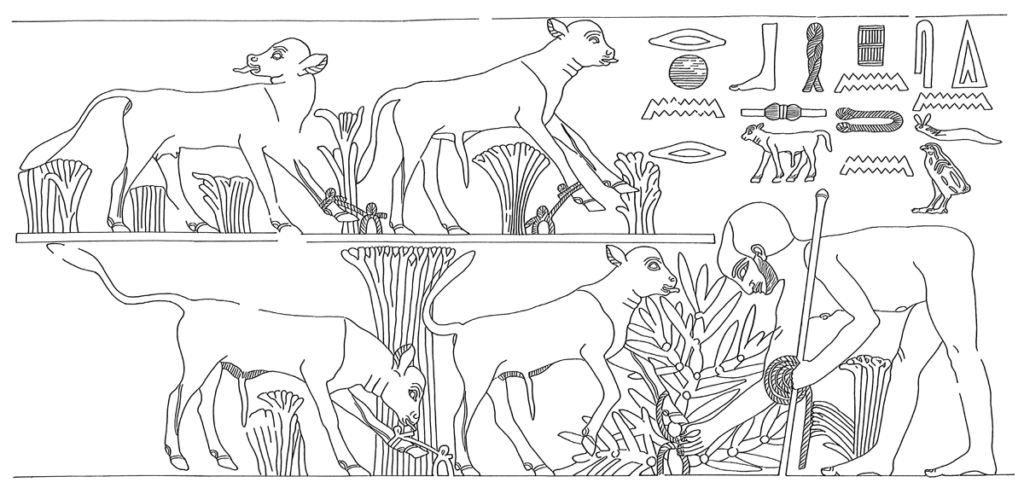
We are excited to announce a new version of the Oxford Expedition to Egypt: Scene-details Database, an ADS collection that has been a valuable resource for…

Back in September 2025, I had the pleasure to attend the CIfA Archaeological Archives Group conference “From Past to Future: Archiving 2000–2025”. My presentation gave an…

Introduction Back in May 2025, we at the ADS issued a survey to explore the possibility of implementing APIs (Application Programming Interfaces) to allow our users…

During the last week of October 2025, I had the opportunity to represent the Archaeology Data Service (ADS) at the International Council on Archives (ICA) Congress…

I’m Dr Ian Wyre and I started working with the Archaeology Data Service as a Digital Archives Assistant in May 2025. I had begun my career…

On 9th and 10th December 2025, I had the opportunity to attend the annual conference organised by the British chapter of Computer Applications and Quantitative Methods…

Back in September, I had the opportunity to attend the ATRIUM Summer School on 3D Models in Archaeology, hosted by the Archaeological Information System of the…

Accessibility… Who is it good for? … Absolutely everyone. That’s right. Everyone. Everyone can benefit from improved accessibility in the digital content we all produce. But…