The following is a Guest Blog authored by Professor Stephen Todd, currently visiting Professor in the Dept of Computing at Goldsmiths, University of London. We’re always interested in how people use our data, and indeed how they want to use or access our data. After preliminary discussions about enabling Cross-origin resource sharing (CORS) to provide direct access to ADS archived files for an xyzviewer, Stephen has been kind enough to write up his current work and wider thoughts for us as a case study.
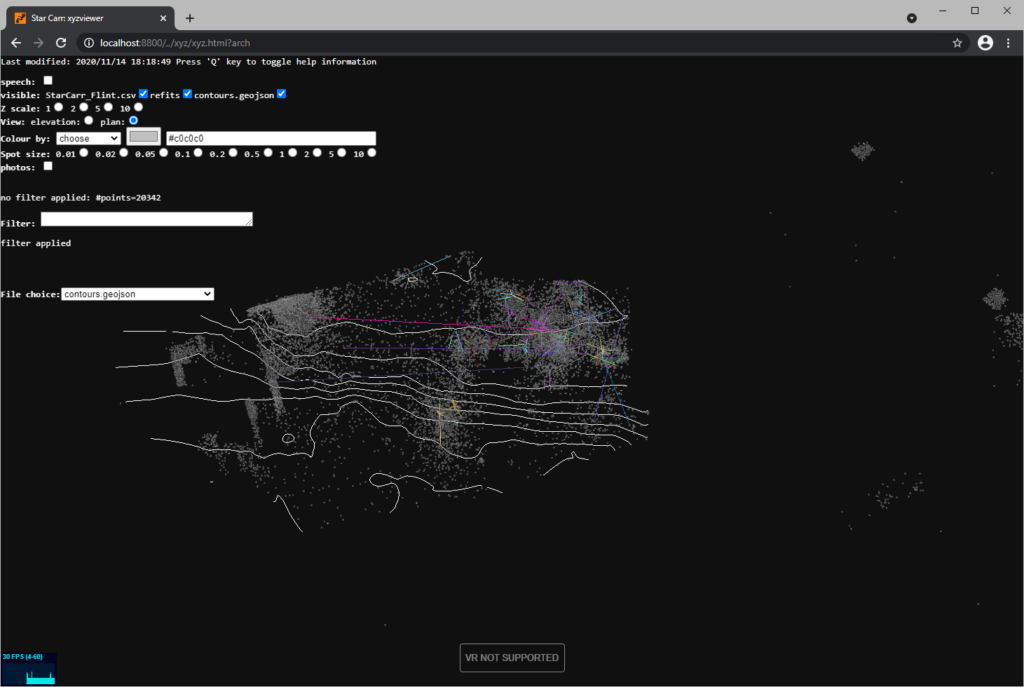
This note discusses how xyziewer permits exploration/visualization of a subset of Star Carr data, and makes some points that arise on collaborative data and the relationship to the Archaeology Data Service, ADS. It is in two parts, the first outlines the capabilities of xyzviewer, and the second more diffuse arising thoughts.
xyzviewer and Star Carr
You can run the code discussed here by visiting https://sjpt.github.io/xyz/xyz?arch. (That url may change in future; that’s part of the discussion in part 2.)
The site you visit contains the xyzviewer code and an extracted subset of Star Carr archive data. The project began in 2018 as a collaboration between the archaeology department at the University of York and the department of computing at Goldsmiths, London. This was before the Star Carr data was published. Almost all the data in the extract is now available on the ADS archive https://doi.org/10.5284/1041580 but we do not currently access the archive directly for reasons discussed below.
xyzviewer capabilities
This is a brief description of the xyzviewer capabilities.
xyzviewer is web based, and so requires no installation. It is a generic program that can load and display .csv, .xlsx, .geojson, .dwf and .ply and .asc lidar files in 3d; not all features of those are supported. It also has tailored code for specific applications, eg to display Star Carr refit data. Data can be loaded from the host site, from the local file store, or from other ‘collaborative’ (discussed below) data repositories.
xyzviewer shows data in realtime 3d, with interaction by mouse, keyboard, or (very limited) voice. It can also show data in VR with appropriate hardware; that includes specialist hardware such as HTC Vive, and also many phones with Google cardboard style VR viewers.
It has capabilities for filtering and colouring options, and can also show photos of each artefact overlaid on their display. (We did not have easily available photos of Star Carr data, so not included in the demo).
xyzviewer allows a user to pick data with the mouse and have details of the selected data displayed.
The implementation uses the webGL and webXR standards, and relies on three.js and other helper libraries.
Reference
The idea was derived from work at the IBM United Kingdom Scientific Centre in Winchester in the mid 1980s; the key concept being data exploration as the combination of data manipulation and data visualization.
Three-dimensional computer graphics for archaeological data exploration: An example from Saxon Southampton, Sarah M.Colley, Stephen J.P.Todd, Neil R.Campling, Journal of Archaeological Science. Volume 15, Issue 1, January 1988, Pages 99-106. https://www.sciencedirect.com/science/article/abs/pii/0305440388900222
xyzviewer and your own data
You can test xyzviewer on your own data by launching https://sjpt.github.io/xyz/xyz and drag-dropping your data files from Explorer or similar onto the xyzviewer canvas. We do not have a formal user guide, but there is information in the xyzviewer notes document.
Future, open collaboration
This section discusses some ideas on how data and programs can improve collaboration between each other, and thus permit improved exploration by a user, and collaboration between different users.
Most of the following contains much more diffuse ideas and points that have arisen from the project above. Most of it applies not just to xyzviewer, ADS and Star Carr, but in much wider contexts. Much of it will be motherhood to some readers, but because different people will be approaching this from different directions I have included it.
Collaborative data
In this section I make the point that for data to have the most benefit requires more than just a public archive of that data (though of course that is a necessary part). The capabilities of programs such as xyzviewer permit exploration of the loaded datasets; this section is about how to explore what datasets are available.
Available by persistent archive reference (PAR)
The first essential for navigable data is that all the datasets should all be available by an agreed persistent reference (PAR).
For long term stability this involves the use of DOIs (Digital Object identifiers), the responsibility of DOI and the archive owner, in case the archive is moved. It also requires persistent references within the archive, for example if the archive is internally reorganised. The resulting PAR will have a ‘front’ part (DOI reference, eg https://doi.org/10.5284/1041580) and ‘back’ part (eg arch-1253-1/dissemination/csv/flint/sc04_15_flint.csv); so the total reference will be something like:
https://doi.org/10.5284/1041580/arch-1253-1/dissemination/csv/flint/sc04_15_flint.csv
This PAR will technically be neither a DOI nor a URL. It will not resolve correctly if typed directly into a browser or if submitted to DOI. However, participating application programs will be able to share and access data in a consistent way using such references.
Pending: One way programs can take advantage of URLs or PARs is by direct access to data given the URL/PAR. xyzviewer could be started to access data from a data server by URL; for example
https://sjpt.github.io/xyz/xyz?arch&startdata=https://archaeologydataservice.ac.uk/catalogue/adsdata/arch-1253-1/dissemination/dxf/vp04-10/vp08_dr110.dxf
would load our standard Star Carr extract data and also the .dxf plan file from ADS. Alternatively, once xyzviewer is running we could copy/paste or drag/drop a url onto it. So we could navigate the Star Carr archive to reach 2008 Plan data and drag/drop (or copy url and paste) the DXF link for Plan of structure [164] in SC23. See video here.
Alternatively, a user may be showing data in xyzviewer or similar on a shared screen in a conference call such as Skype. Another call member is interested in some particular data. This second person finds the URL reference in the archive and copies it into the conference call message channel. The first user copies it from there onto xyzviewer; all the call members can now see this data.
The previous paragraphs are marked ‘pending’ as security restrictions (Cross-origin resource sharing (CORS) rules) prevent it working. We are discussing relaxation of these restrictions for ADS data which should benefit xyzviewer and any other web based programs that want full collaborative access to the service. The examples above do work for our experimental code at the moment by use of a local proxy server. See the appendix for more technical detail.
Navigable
Fullest use of archive data requires it to be easily navigable.
Outside the viewer
This includes navigation by existing methods outside any collaborating program, and then some form of federation between the archive and program. The copy/paste example above is a very simple form of such federation. Even closer collaboration can be considered with more work on both sides; for example the right-click context menu on the data could have an additional ‘copy to xyzviewer’ entry.
Index of available datasets
However, it can be more convenient if the navigation to find the relevant datasets within the archive can be from within the viewer program. This is best done if the archive provides an index file with (relative) URL pointers to all available datasets. This would likely be a simple CSV or JSON file. The user can quickly search using the viewer program accessing this index to find appropriate data.
The Star Carr archive already has some such metadata files: for example for sections data. Where such metadata is not directly available it can sometimes be concocted by screen scraping.
Search engine
The archive should have good internal search for finding datasets, and also make sure that search engines such as Google have good access.
For example there is the major csv dataset for flint finds. I would hope that a search for ‘star carr flint data csv‘ on Google would find it, and so would a search on ADS. Also, that there would be search within the Star Carr archive.
Collaborative programs
The previous section discussed how to make collaborative data so that programs could make the best use of it. This discusses collaboration between programs. Each of these is quite a technical issue in its own right, so I do not go into details here, just highlight points for consideration.
Program structure
Programs should be as generic as possible, with clear plugin interface and API. This means that other programmers can extend a program, and the program can easily take advantage of other code and services. (xyzviewer does not do this as clearly as it should. For example, we have added a refit program that is specific to the Star Carr program, but the plugin mechanism is not yet completely defined.)
xyzviewer does benefit significantly from other open programs and libraries; three.js for the major graphics, and programs for the loading of dxf, xlsx, ply and other file formats.
Saving and sharing settings
Often one user of a program will want to share settings etc with other users. This applies to a continuum from a few simple settings, complete sets of urls, extra data (such as colouring style files), code snippets and full plugins. This can be done in various ways each with pros and cons: local files, local browser storage, server files.
Communicating federated programs
Federation is where two separate programs work together, without full integration into a single program. This often allows a user to work with more than one program at the same time in a fairly fluid manner, without the development expense of full integration of those programs. Most important is a shared understanding of what is to be communicated, and at a lower level how to communicate (files, sockets, pipes, clipboard etc).
The copy and paste of URLs discussed above is a very basic form of federation; it had the advantage that it required no extra work on the data archive side.
Also of potential value is communication between multiple copies of the same program. So for example several users of xyzviewer might (not can) connect in a session so they could more easily collaborate and share their exploration. The technology for this is completely standard in the games world, but not often exploited in the data exploration world.
Appendix
CORS technical detail
An installed application can access any data via its URL. However, for security reasons there are restrictions on web browser based programs (such as xyzviewer) hosted on one domain accessing data or code hosted on a different one (CORS). This means that xyzviewer cannot currently directly use data hosted at ADS; only the extract co-hosted with the xyzviewer code, or locally stored data.
There are various ways around this. One is that a data host can explicitly make pages available to web applications by providing appropriate CORS headers, as we are discussing this with ADS. As an example from a different application area, all public protein data hosted at the protein data bank (PDB) is enabled for access from any web program. For example https://sjpt.github.io/xyz/xyz?pdb=4BCU will use xyzviewer as a very basic pdb viewer, dynamically loading 4BCU.pdb from the data bank. Anyone providing open data with a view to maximum collaboration should make sure their data is open to read access in this way.
Chrome (and maybe other browsers) can be launched to avoid the cross-access restrictions; using the flags
--disable-web-security --user-data-dir="..."
This essentially makes Chrome applications run like any other installed application. This opens all applications that run on that browser instance to the security loopholes the cross-origin principle is meant to avoid. It should only be used for experimental purposes on a separate instance of Chrome that is not used for sensitive applications such as email. The --user-data-dir to a separate profile directory ensures that a separate instance of Chrome is launched (one instance per profile), but care is still needed which Chrome instance a particular window belongs to.
Another possibility is to use a proxy server. We run a local proxy server for development and experimentation. There are related security issues so we do not recommend this as a general solution.
local vs cloud
General comments:
- local may be files or browser storage
- files more convenient to user but access from web programs is very limited
- local requires work to get program/data downloaded
- user drag/drop of a directory is sufficient for read access, the code can then navigate under the dragged directory and read the files
- local easier to experiment with program/data (eg use other programs for data conversions)
- cloud/server makes for easier dissemination and (potentially) sharing
- can use a hybrid; eg load from server but save/cache locally


