
The ADS has (for nearly 25 years!) been providing free access to resources deposited with us. We put them online in open/accessible formats, people use them, and people cite them. We know people use them because we have data on page views and downloads. Some things are used a great deal; often high profile research resources that always gain alot of mentions in literature and social media. Others have more of a cult following, but are still used sporadically.
All these access statistics always make a good basic demonstration of impact; we can pass them onto project funders and stakeholders to demonstrate quantitative success. However the follow-up questions normally enquire as to “who” is using this data, and for what purposes. The ADS have many ambitions in regards to its (meta)data, but facilitating and demonstrating this re-use is a high priority. Over the last year I’ve had a chance to think more about what we could and should be doing, and how it can help us, our users, and depositors make more of the situation…
The key to this are the Digital Object Identifiers (DOIs) we use. For those unaware, ADS use DataCite DOIs through our membership of a consortium lead by the British Library. We create DOIs for:
- All our deposited collections
- Upon request, distinct entities within a collection
- All unpublished reports
- Journal articles
These DOIs are registered with DataCite, and in doing so we also pass on key metadata for the Object (who created it, when it as created, where it realtes to etc). This metadata is then searchable in the DataCite interface, alongside records from other repositories that are part of the DataCite community such as Zenodo or Dryad.
When users use ADS resources they should be citing the DOI. For example when using material from the ever-popular Roman Rural Settlement project, any use of the data should follow our guidelines, for example:
Martyn Allen, Nathan Blick, Tom Brindle, Tim Evans, Michael Fulford, Neil Holbrook, Lisa Lodwick, Julian D Richards, Alex Smith (2018) The Rural Settlement of Roman Britain: an online resource [data-set]. York: Archaeology Data Service [distributor] https://doi.org/10.5284/1030449
Or for a Journal article:
Sparey-Green, C. (2002). Excavations on the SE defences and extramural settlement of Little Chester, 1971-2. Introduction. The Derbyshire Archaeological Journal 122. Vol 122, pp. 1-10. https://doi.org/10.5284/1066616
There are tools available from DataCite to reformat these into nearly all forms of Bibliographic reference, but it’s important to emphasise that any citation or reference should include the DOI and not the URL that appears in a web browser. For example it should be https://doi.org/10.5284/1066616 and never https://archaeologydataservice.ac.uk/library/browse/details.xhtml?recordId=3202768
Why? Primarily the DOI is persistent. No matter what happens to ADS applications in the future (for example an update to the Library may lead to us not using details.xhtml any more), a reference to the DOI will always take you to where the content is. Secondly, and most inportantly in this case it allows us, via a range of tools, to identifiy where our DOIs are being used.
One such tool is the DataCite Event API, a prototype developed in collaboration with Crossref to track citations of DataCite DOIs quoted as sources in academic papers. A quick search of this for ADS DOIs shows for example:
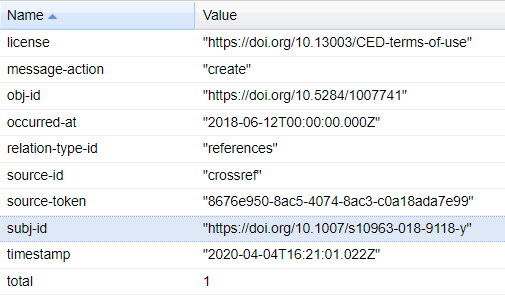
In this case the paper ‘Approaches to Interpreting Mesolithic Mobility and Settlement in Britain and Ireland’ published in the Journal of World Prehistory cited Wessex Archaeology (2006). Engand’s Historic Seascapes Final Report https://doi.org/10.5284/1007741.
In addition, there’s also the incredibly powerful CrossRef Event Data, a set of APIs that captures and records events that occur all over the web. This includes not only published articles but also Twitter and Wikipedia (including WikiData), So for example I can see
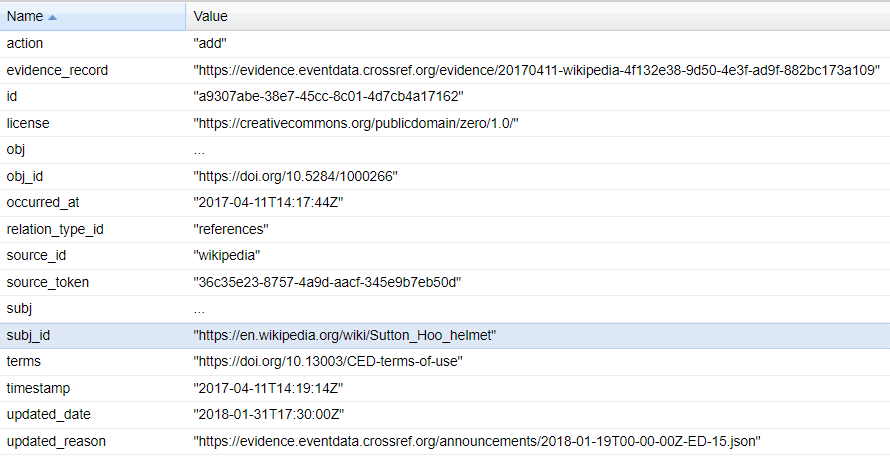
In this case, the Wikipedia article on the Sutton Hoo helmet cites Martin Carver’s data from the Sutton Hoo Research Project.
Capturing this sort of reuse, and mentions of resources in Twitter conversations (919 and counting) is to my mind a useful indicator not only of reuse, but a glimpse into the sort of conversations people may be having about our digital Objects.
The next step is for us to build a method to pull data from these APIs and incorporate back into our metadata as a dynamic process. This would mean that this page (for example) https://archaeologydataservice.ac.uk/archives/view/romangl/metadata.cfm is refreshed with information where we can demonstrate that https://doi.org/10.5284/1030449 is ‘Cited By’ XXX. Who knows, this could even be extended as an option to email a deposition when their data has been cited so that they know their data is being actively used.
Which brings me back to the title of this blog. The idea of a virtuous academic circle lies at the heart of what it is to publish – you publish your words/data, someone else uses it and cites it, you know they’ve used it (however this may be), this encourages you to publish more as you know your work must have some value. It also taps into what is at the core of what the ADS was set up to do: the archive/record is there to be used and maybe (hopefully?) reinterpreted and re-purposed. The archive needs to be used, otherwise there is arguably no point in having the archive.
However, without wanting to mangle my shapes, I think this model is more complex and more in-line with the sort of graph theory / social network analysis that is now de riguer. It’s good to know where our resources are being cited, but there’s a whole bigger world of possible study. What sort of Journals are ADS resources cited in, what sort of ADS resources are cited (e.g. is anyone citing the raw data?), what topics do these represent, who is citing etc etc. There’s material there for a new wave of study about citation habits and biases, or at the very least a PhD…
Anyway, for this to happen please remember to cite the DOI!


