
Since a Beta release back in March 2017 we’ve received a great deal of feedback on the ADS Library application. We know it’s used intensively, with over 120,000 downloads in 2019, but as with any IT application there are places it can be improved!
For the uninitiated, the ADS Library was the outcome of a Historic England funded project to ensure the longevity of the British and Irish Archaeological Bibliography (BIAB). BIAB had traditionally been maintained by the CBA, with records added into the database by hand from extant sources (see Heyworth 1992). As this approach became less sustainable in the digital age, it was also deemed advisable to combine this dataset with the growing number of digital unpublished reports and journals and monographs held by the ADS, the former mainly derived through material uploaded to the OASIS system. This was also an opportunity for the ADS to align its records with BIAB, and to have a single interface to cross-search all written works it held (traditionally, files from unpublished and published works sat in different databases). Having a unified database, with access to free copies of published and unpublished reports has also been in line with Historic England’s HIAS Principle 4: ‘Investigative research data or knowledge should be readily uploaded, validated and accessed online’.
A considerable amount of work went into this undertaking: over 100,000 records from BIAB, the database of unpublished fieldwork reports, and the individual datasets behind each journal collection all had to be configured into a single database, and “messy” data cleaned and reconciled. This was particularly problematic when trying to reconcile authors, with no form of unique persistent identifier in any dataset.
As with many developments, pragmatic decisions had to be made to ensure we had an application that worked, even if that was at a basic level. However, with a bit more time, the benefit of hindsight, and the aforementioned feedback, we’ve been able to revisit the Library and implement a number of changes and improvements. I’ve listed the major ones below, along with some rationale. In addition, there’s still some things that we’re planning to do, but need some more time to refine. Just so you can see where the Library is heading I’ve also reported on these.
Change 1: Interface improvements and Accessibility
These include:
- A nice spangly carousel for the home page which shows off some featured collections.
- We’ve made the web application conform to Web Content Accessibility Guidelines (WCAG) 2 requirements (thanks to Teagan and Katie, who have been looking at site-wide Accessibility as a priority).
- More help/guidance on screen, and tweaks to try and make the interface more intuitive (larger icons, more text on screen explaining what things are!).
- More options to filter and order results.
Change 2: Usage Statistics
Long awaited! We have collected usage data via Matomo (formerly Piwik) for several years. Presenting these for formal archives has been straightforward, however for journals and grey literature it’s always been slightly trickier to aggregate in a meaningful sense. However, we’ve succeeded in being able to pull out and present this information per Series (a Series is a defined collection, for example “Cotswold Archaeology unpublished reports” or “CBA Research Reports”), and for the Library as a whole. For simplicity and consistency, we’ve set the application to display Series only as far back as 2018 (because of a historical changes to the way we had information stored, it’s harder to break the historic stats down into defined sub-groups), but the Library as a whole can be viewed going back to 2014 to give a sense of historical trends. These are ‘real’ statistics, and filter out web crawlers, ADS IP addresses etc.
Change 3: A refocus on DOIs
Since we embraced DOIs back in 2011, this ubiquitous persistent digital identifier has been a mainstay of how we present information for citation. We’ve done a number of improvements both in the ADS Library application and back-end, that build on this work:
- DOIs are now minted for Journal articles where we hold a digital copy and a DOI has not already been created by the publisher. These are currently limited to entries which have a minimum of information, such as Author, and Page Start/End
- The DOI is now easier to see! It now follows the normal bibliographic style citation in the title of each entry.
- We now also use the most recent version of the DataCite metadata standard
Change 4: Help for citation formats
Thanks to Change 3, we can leverage the metadata in DataCite a bit more. A simple hyperlink over to DataCite allows the metadata to be reformatted into a variety of citation formats (APA, Harvard BibTeX etc). DataCite also has the option to download the metadata record as XML or JSON (more on the possibilities for this later)
Change 5: ORCIDS and other PIDs
We now display ORCIDS, where we have them recorded for a named author (about 200 entries in the database). In the short term this will help us maintain consistency in allocating records to the correct person as new information is added from OASIS or elsewhere. We’re also collecting other identifiers for people such as ISNIs and WikiData (e.g. https://www.wikidata.org/wiki/Q30688732). Longer term, it means our collection and metadata are just a bit more interoperable with other systems… In addition, every author page now displays any information we have on an individual, plus advice on what to do if you want to create an ORCID (i’s free!). We’re really keen to augment records wherever possible, so if you have an ORCID that we don’t know about then please get in touch!
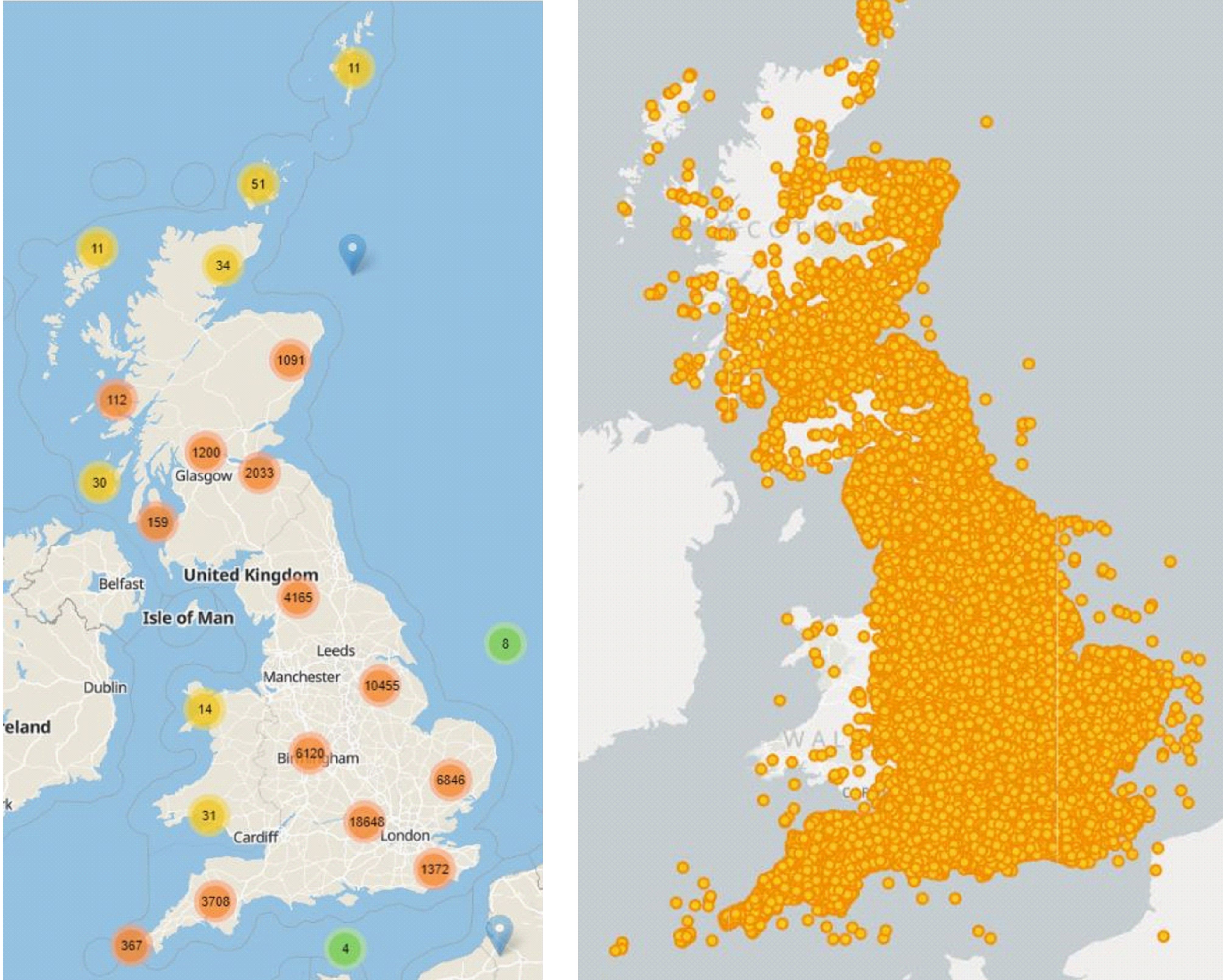
Ambition 1: Spatial
Our most requested feature is to see everything on a map, or at least be able to do more to filter/visualise results by area. We want this too, and we’re nearly there…. We’ve been looking at ways to surface our records with spatial metadata into a single map (see below). However we’re still thinking about:
- Approach to use: WMS (server) or GeoJSON (client)? Which works best for clustered records, load times etc etc. How do we best add filters in so people can see records per organisation, thematic period etc.
- How do we rebuild this export to be dynamic? Record are added frequently, do we set the rebuild to be daily, weekly etc?
- We can see some records have errors in the coordinates (why are there points in France!?) – do we try and clean these ourselves, or wait for people to tell us?
- Lack of consistency in area names: e.g. “Hampshire” and “Hampshire Somerset” both exist in the combined dataset. We need time + resources to clean these…..
- A lack of any defined spatial metadata for journals + monographs (see below)
All of these issues can (and will be) addressed, we just need time to investigate and resolve.
Ambition 2: Augmenting metadata
We love the Journals and Monographs we hold, and from the useage stats so it seems do our users. The metadata we’ve traditionally asked for has been purely bibliographic, which is limiting for when you want to see all records for area x”. One of the things we would like to add to our service agreement with depositors of these Series is the capability for ADS to create comprehensive metadata A few things we’ve been looking at include:
- Named Entity Recognition (NER) of title/abstract
- NLP of PDFs
… and then reconciling terms to controlled vocabularies (such as OS, TGN, Geonames, Pleiades). This also extends into interesting areas such as annotation, and thinking about new procedures for how and when we add to metadata. For example:
Hadley, D. M. and Richards, J. D., (2018). In search of the Viking Great Army: beyond the winter camps. Medieval Settlement Research 33. Vol 33, pp. 1-17.
Could have either or both of
To record the place of Torksey, but do we also want traditional county – district – parish stored in the database, and then what to do about non-UK records? Do we want to go truly spatial, and have searches defined not by a string but a geometry? Whatever we decide then has an impact on the back-end database (including moving to a new db), and any search interface we build on top of this (SOLR or Elasticsearch). As ever, we just need a bit more time to think and test…
Ambition 3: Connecting things up
Preliminary tests with the DataCite and CrossRef public APIs has show that we can track where ‘our’ DOIs are being cited in other resources. For example we can see that https://doi.org/10.5284/1008287 has been cited by https://doi.org/10.1007/978-3-319-53160-1_28. The next step is to create a method to feed this metadata back into our database, and render this information on the record page. We then have a dynamic way not only to show downloads, but specific citation and re-use case studies. We’re also keeping an eye on http://www.scholix.org/about
Ambition 4: Sharing metadata
We’ve always been keen on sharing our metadata wherever possible. At the time of writing we do so via the following methods:
- OAI-PMH for which feeds Series records into the Keepers Registry
- OAI-PMH with feeds Maritime records into the MEDIN Data ‘portal’
- WAF with XML for feeding grey literature records into ARIADNEPLus
- Various ‘custom’ XML/CSV functions to provide depositers/users
As we’ve seen already, DataCite provides quite a powerful service for metadata (DataCite metadata standard is comprehensive). So there’s potentially a lot more we could do in terms of using/linking to the various tools (such as the public API) to allow an alternative search of our metadata.
Ambition 5: Granular useage statistics
Another rainy day task – how to reconcile a very long URL request, normally https://mydomain/folder/folder/folder/myfile.pdf back to the ADS Object Management System (OMS) which holds the Unique Identifier for the file in our repository system (e.g. 1234567). We can do this on the fly (as we know that 1234567 = myfile.pdf), but requires a bit of SQL acrobatics to do so, and on a data store of millions of records this can be a bit inefficient. Or do we wait for a longer term ambition to overhaul the infrastructure of how we display our digital objects?
Final thoughts
As ever, thanks to those that have read this far. I hope it has shed some light on the thought processes behind what you can/can’t see in the Library. I’m more than happy to field any questions, or if anyone has any advice based on their work or research, please do drop us a line!
References
Heyworth, M. (1992). The British Archaeological Bibliography: a fully computerised service in archaeology. In G. Lock and J. Moffet (Eds.). Computer Applications and Quantitative Methods in Archaeology. BAR, International Series 577. Oxford: British Archaeological Reports, pp. 15-20.

