The following blog is simply a musing on our historic approaches to archiving formatted text files, prompted by a user enquiry into “best formats” for preservation of their reports, and my role at the ADS as keeping abreast of said formats and our internal policies.
Many years ago, in a meeting of the curatorial and technical team (CATTS), conversation veered towards our procedures for handling text documents. That is files whose significant properties were formatted text/typeset reports, as opposed to plain text files (with ascii or UTF-8 encoding) often used for exporting or importing of data. One colleague, half in jest, commented that as the Archaeology Data Service our focus should be on the literal data as understood in computer science – the individual pieces of information being generated from various instruments or collected in databases. Reports it may be argued are the interpretation of that data, but often not the raw data itself.
I’ll leave that tricky debate there, but increasingly in archaeological fieldwork and archiving practice, it is clear that “the report” is still a a key product often combining statements of fact and observation, manipulations of raw data such as tables and images. In addition, it is also a type of data (if I can use that word!) that comes to us in increasing volumes. A quick examination of the types of files deposited with us over the last 20 years shows that we’ve received:
- 16,193 .doc files
- 78,611 .pdf files
- 798 .docx files
- 519 .rtf files
- 61 .odt files
- 37 .wpd files
In truth, some of these may not actually be formatted text reports – people have always loved putting tables and images into word documents, and latterly some of the PDFs we receive are simply exports of raster/vector images from programs such as Illustrator or CorelDraw. Indeed, the problems of PDF files have been discussed at length in other blogs.
Although not in the same league as images (we’ve accessioned 268,000+ jpegs and 332,000+ tiffs) and even discounting PDFs, it’s still significantly more than other, more standard types of data for example:
- 5526 .xls files
- 1067 .mdb files
- 3884 shapefiles
- 2196 .csv files
In short, we’ve received alot of these files but what have we done with them?
Historically, the ADS initially looked at saving the documents it did receive as TXT files, although as retention of formatting became an issue looked to RTF (Rich Text Format – a tagged textual format developed by Microsoft) as a preservation format. The following overview is is taken from the Guides to Good Practice:
“Although a largely human readable plain text format, and therefore suitable for both presentation and preservation, there are compatibility issues regarding formatting (e.g. textboxes and tables) when opening files in different word processing packages. ”
With these issues in mind, in 2004(ish) the ADS moved to the relatively new range of Open XML formats developed by OpenOffice.org and used by OpenOffice/StarOffice. Initially sxw (used by from version 1.0 to version 2.0 of OpenOffice) and latterly ODT (Open Document Text, part of the OpenDocument Format or ODF, an ISO standard ISO/IEC 26300:2006 for XML-based office document formats). Indeed, the move from RTF to ODT formed one of the ADS’ first large-scale migrations, being applied to all legacy archives as part of our Preservation Policy. The small numbers of SXW files were migrated in an ADS-wide update and consistency check in 2011. As an aside, in is interesting to note the relatively small number of ODT files we’ve accessioned since formally embracing ODT (it became an accepted format for depositions in 2005); as the stats above show we’ve only ever been sent 61! In part this may be historical, but perhaps more an indication of the default use of MS formats by many in the archaeological community.
When I started at the ADS in Summer of 2006 procedures on how to deal with ODT files was often debated, as an ODT is essentially a compressed zip file containing separate style, text (as XML) and embedded content (e.g. images) files. Concerns were often raised as to whether storing ODTs in their zipped state was adequate for preservation, and whether we should be storing them unzipped, and the problems of dealing and storing archival versions of their composite elements (see below).
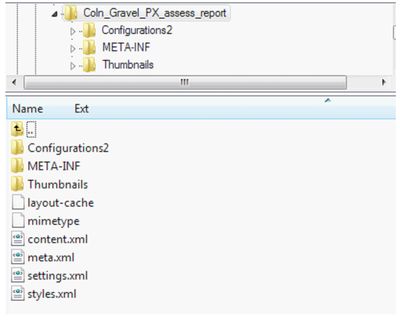
For a brief period word processed documents were thus saved as ODT but stored unzipped, but addition with any images separately archived as tiff. After much debate, this solution was refined to storing the compressed ODT element, and any raster images as additional TIF (see below). This decision was not taken lightly, as storage of a compressed format went against our standard practice – however in this case it was felt that by storing the images in an uncompressed preservation format (TIF) outside of the ODT wrapper mitigated against any data loss, the rest of the package being a series of XML documents.
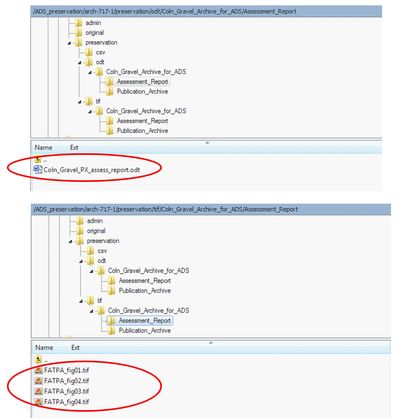
This procedure carried on until around 2009/2010, we’d often noticed a few problems with Microsoft DOC and RTF conversions to ODT, often based around loss of formatting. There’s an interesting page here on various bits of MS functionality/formatting that can’t be retained in ODT. Obviously this comes from a very pro-MS viewpoint (and begs wider questions about Word!), but illustrates the point. Quite often we were forced to make small alterations in files to ensure we were preserving the ‘significant properties’ of a file.
Then MS launched its flavour of Open XML DOCX, PPTX, XLSX (collectively called OpenXML or OOXML). The trials and tribulations of which are covered pretty succinctly in two blogs here and here. Whilst we were interested in the format, from perusing various blogs and forums we had some concerns over the rumours of embedding of binary rather than just XML, and quite how ‘open’ the source code would be.
Our reservations were somewhat abated when OOXML moved towards gaining ISO status, and in 2010/2011 we made the significant decision to use DOCX as well as ODT. The decision on which format to use being dictated by the deposition format, and a decision by the archivist on which output did the best job of retaining significant properties. Normally ODT files have been left in that format, with DOCX being used for the MS flavours. Following our now established practice, any embedded images were to be stored as uncompressed TIF. Aside from the ongoing headache caused by PDF files, we were relatively happy we had a solution that combined best practice and pragmatism.
However, closer and more recent investigation on the nature of DOCX has revealed that the format is not as straightforward as first envisioned, a consequence of some difficulties accrediting the format as an ISO. As numerous sources record, within the ISO body there was community intransigence to DOCX based both on some of the ISO member’s use of ODF (i.e. why do we need another XML-based format?), as well as some “non-open” parts of the format. A compromise was reached, and to quote a good overview of the subject:
“it was proposed that OOXML be split into two sub-standards, namely ISO 29500 Transitional, and ISO 29500 Strict. The Strict version was that which was accepted by ISO, and the Transitional version was fairly granted to Microsoft to allow them to slowly curb out older features from the closed source days.”
A problem arose when Microsoft decided not to fully implement the Strict version of the standard in Office 2010. Thus when you save a document in MS Office 2010 or prior in any of the ‘X’ formats, you are not saving them in the advertised OpenXML format. Although MS 2013 has an option to save as strict and transitional, somewhat frustratingly, transitional is set as default.
When this was first noted here at the ADS, this caused a moment of mild alarm. In a recent tech-upgrade we were default using Office 2010 and thus only the transitional ISO. The ISO that we’d put our trust in was only a stepping stone to a truly open format! However, the panic soon abated, what had other archives been doing prior to the release of MS Office 2013?
The sense of belonging to a wider problem helped soften the blow, and in a subsequent discussion among the team any final serious doubts were assuaged by the ADS’ policy of Preservation by Migration. Put simply, when we upgrade to a version of Office (or OpenOffice package, as later versions of OpenOffice support both the Transitional and Strict versions, a sign that despite reservations a degree of pragmatism in the community has led to them becoming ‘accepted’ formats) that support ISO 29500 Strict, it will be time to schedule in a batch migration from Transitional to Strict. A course of action that will be made easier than ever before by the holdings of out Object Management System (OMS), a database which records the location and technical specifications of all files within the archive. As I write I can write a query to show me all the preservation DOCX files we hold (8573 if you’re interested).
What have we learnt? In short it’s that digital preservation never stands still, and in this case has to be reactive. Although we feel slightly abashed by (inadvertently) failing to migrate to the Strict ISO there was little else we could do at the time with the knowledge and facilities we had. Furthermore, although ODT has proved effective for documents created in OpenOffice, it hasn’t always a practical solution to all the files we were given. Having said that, it may be that in, say, 5 years time we don’t migrate to DOCX but investigate later versions of ODF, or perhaps even another format altogether….