While rationalising old and orphaned files on the ADS servers, I stumbled upon an old index.html file for a previous version of the website. Similar to discovering a long forgotten photograph in the attic, this led me down the meandering path of memory lane. However unlike a photograph, reconstructing the look and feel of a web page requires some fiddling to correctly associate the style sheets and any server side includes. After a few cut and paste commands replacing server side includes with actual HTML and a directory search for the missing stylesheet, the old homepage was back up again in all of its glory.
Even though I spent my first four years at ADS using this homepage it looked totally foreign to me. The structure was confused, the javascript unnecessary and the style was uninspired. The page was functional, but left a lot to be desired compared to the structure and clarity of the present version. The backend framework and systems that make up the current website also make it manageable and easy to update, compared to the organic, disjointed structure of the previous website which led to headache inducing updates as seemingly insignificant modifications led to unanticipated bugs (or features depending on your preferred coping mechanism).
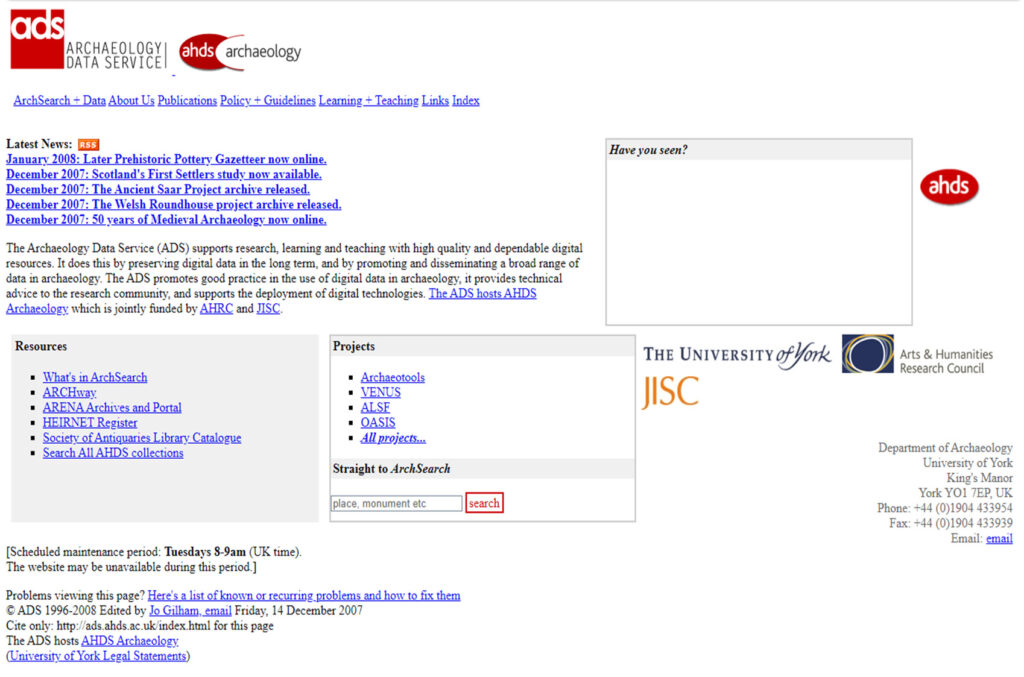
Revisionist liberties are being taken with regards to this webpage review, and everything wasn’t as bad as I just laid out. The reality is web sites have a tendency to grow and add complexities, and therefore their structures begin to creak under the weight of new content. For that period in the history of the ADS, the website fulfilled all the requirements of the users and its curators. The further you look back at a dynamic medium such as the web, the more nits you are able to pick. And with a hankering for more nits, I decided to see how deep within the ADS webpage stratigraphy I could dig. I had begun wall chasing, using command-line tools such as find and grep to hopefully excavate an older version of the homepage. Unfortunately no actual HTML could be found, but I was able to find a record of the original website in the form of a screenshot.
However, when “excavating” old web content, we have a tool that has no real world analogy, the Internet Archive’s Wayback Machine. It is effectively a digital “archive” of the web, with versions of web pages going back to the very beginning of the web as we know it. This allows us to go back and view old web page content in its partial original glory. Partial because images and style are not always included with the snapshot. The earliest version of the ADS website (back then at the http://ads.ahds.ac.uk address) ironically points at an Internet Archaeology landing page (the internet archaeology of the ADS leads to Internet Archaeology).

To get to the earliest “ADS-only” homepage, we have to fast forward to December 1998, which gives us the original HTML (albeit slightly modified) that built the screenshot. With this HTML, we could theoretically revive this ancient version of the ADS homepage, although some updating of the image sources and style sheets would be necessary. Performing a type of archaeological reconstruction, we could use the above screenshot to inform us how to rebuild the HTML and images for the now lost webpage. The Wayback Machine also scraped other pages, such as earlier versions of Archsearch. A little more searching for old screenshots also turned up this gem (notice the vintage Netscape Navigator window), which could be used in further web page reconstructions.
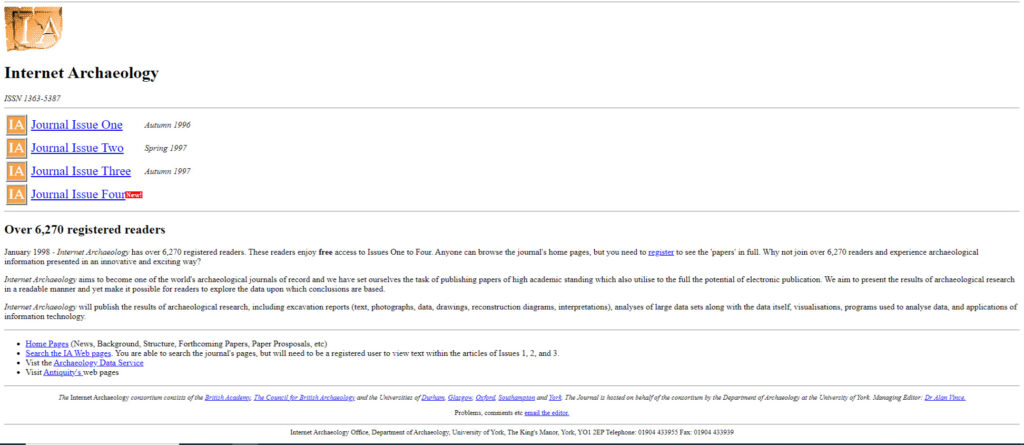
A timeline of specific ADS web pages could easily be presented in the original HTML, providing a sort of typological gallery of web design at the ADS. However, the utility of these kinds of web page reconstructions barely goes beyond a novelty, as most web interfaces within the ADS are thought of as temporary.
We (and most of our users) are more interested in the underlying data, which we present from a transient interface or shop window. Like museums, we sometimes change the layout but that data and our archives remain static. Unlike museums though, we can convert and duplicate our content to ensure its long term preservability, a capability any museum would surely love to have. A real world Wayback Machine would also probably be pretty nice too.


