ADS blog
The Internet Archaeology of the ADS
While rationalising old and orphaned files on the ADS servers, I stumbled upon an old index.html file for a previous version of the website. Similar to…
While rationalising old and orphaned files on the ADS servers, I stumbled upon an old index.html file for a previous version of the website. Similar to…
With the SENESCHAL project finally wrapped up, we thought it would be good to do a final post on how we implemented the SENESCHAL vocabularies into…
An online presence is just the tip of the ADS iceberg, but as such we still rely on search engines to direct traffic to our archived…
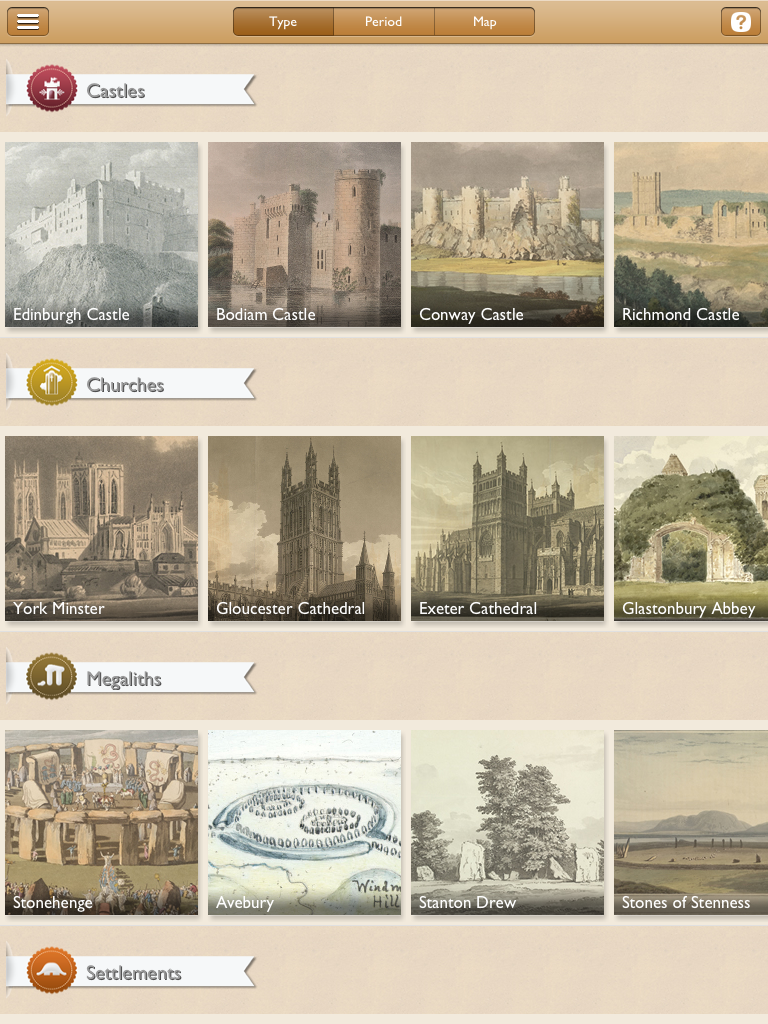
About a year ago the ADS was approached by the British Library (BL) about joining up to develop an mobile app together. A good relationship had…

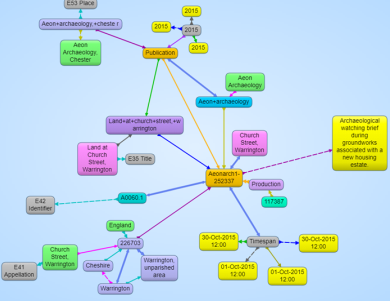
At the 7th World Archaeological Congress in Jordan, Martin Doerr raised a concern about the Linked Open Data world that was being advocated in our session.…
The release of the SENESCHAL vocabularies as Linked Open Data is a very exciting development for practitioners of archaeological linked data. This is the first step…
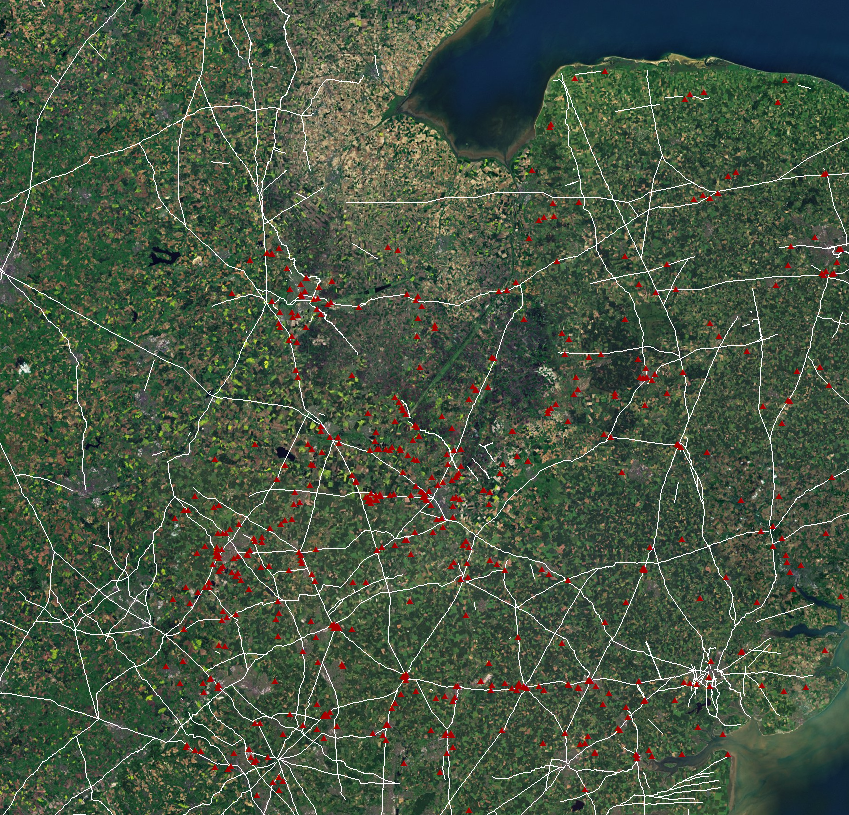
This is the first of a two-part blog – the second will be a more detailed overview of the technologies involved in the digital dissemination –…
The other week I had the opportunity to participate in the SPRUCE Hackathon hosted by Leeds University. Hackathons are an opportunity for developers to get together and…
The announcement of the Digital Preservation Coalition (DPC) awards shortlist is always greeted with some excitement the digital community, but this year’s list was particularly well…
For more than fifteen years the ADS has been working to serve its users, both by acting as a long-term repository for valuable archaeological data and…