The release of the SENESCHAL vocabularies as Linked Open Data is a very exciting development for practitioners of archaeological linked data. This is the first step in![]() enabling the proper alignment of UK archaeological terms for our archive metadata. Before SENESCHAL, we had no authoritative vocabularies to align our Linked Open Data with, so string literals were used based on what was recorded in a Collection Management System (CMS). This is obviously less than ideal and leaves this data exposed to the pitfalls of a pre-Linked Open Data world, such as spelling mistakes and unreferenceable terms, which makes true interoperability much more difficult.
enabling the proper alignment of UK archaeological terms for our archive metadata. Before SENESCHAL, we had no authoritative vocabularies to align our Linked Open Data with, so string literals were used based on what was recorded in a Collection Management System (CMS). This is obviously less than ideal and leaves this data exposed to the pitfalls of a pre-Linked Open Data world, such as spelling mistakes and unreferenceable terms, which makes true interoperability much more difficult.
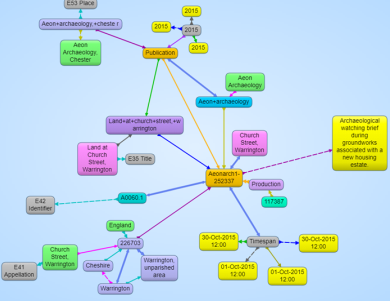
An example of this issue in ADS’s current Linked Open Data for archives can be seen in the Royal Anne Galley Marine Environmental Assessment (RAGMEA) metadata. A screen shot of that is below:
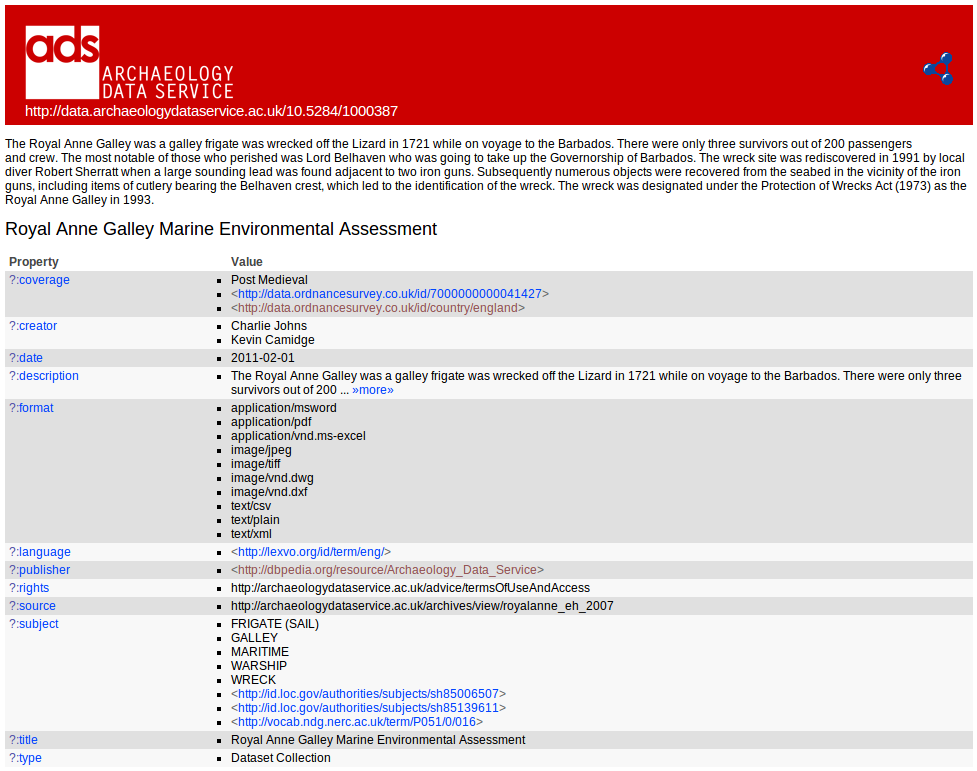
The eagle eyed readers will notice that in our DC Subject field we have a mix of string literals and URIs. One vocabulary we use for our archive metadata is the Library of Congress (LoC) subject headings, which is a legacy of the old AHDS days. Even though this vocabulary wasn’t originally meant for describing archaeological monuments, events or objects, it still does a decent job of doing just that. Conveniently for us the LoC made their Subject Headings available as linked data, which enabled us to align our archive metadata with those concepts in a consistent, dereferenceable manner. That allowed us to link the RAGMEA archive to related LoC terms in a proper linked data kind of way. Being a maritime archive, the RAGMEA archive also had subject values from the MEDIN/NERC subject vocabulary, which they have also published as linked data. Having two vocabularies represented as linked data was a good start, but the big one that we at the ADS have been holding out for, which is also the most used vocabulary in our archive metadata, was the English Heritage Thesaurus of Monument Terms.
With the work done by the SENESCHAL project, we are finally able to begin aligning our archive metadata with national monument and period terms accurately and consistently. Accomplishing this with our existing archive metadata will be automated using a process of firing off SPARQL queries with the CMS terms and then associating the resulting node URIs with the CMS metadata. This was previously done for all the place names in our archive metadata by doing lookups into the Ordnance Survey and Geonames SPARQL endpoints and associating the resultant linked data node with each archive. This was obviously not perfect, since the assumption that place names (or any free text field) are never misspelled is a naive one, but the amount of terms that didn’t return a perfect match from the SPARQL query was only around 10%. This will likely be the same for any lookups to the SENESHCAL vocabulary, since we can’t expect 100% spelling accuracy for our subject terms in the CMS since they are free text fields. The lookup process was accomplished with a simple Java program to grab values out of the CMS database, construct SPARQL queries with those values, parse the resulting XML and associate the values node/URI with that archive.
However, going forward we can improve the process by engaging in the alignment step at an earlier stage, like when the digital archivist is actually creating the metadata rather than after the fact. The plan is to integrate the SPARQL lookup classes to allow digital archivists to dynamically look up thesaurus terms in the SENESCHAL outputs. This will also be done with the place names against Ordnance Survey and Geonames, but the Thesaurus of Monument Terms and other SENESCHAL outputs will be the more useful since they are extensively used in every archive. Aligning our metadata in this way will increase the re-usability of our archive metadata, since the concepts covered in the SENESCHAL outputs (monuments, periods, objects, etc) are key to archaeological research. However the immediate value of a Monument Term lookup within the CMS is more accurate metadata for our archives since we’ll effectively be able to associate a controlled vocabulary from dynamic lookups to a domain authority. The fact that the vocabularies are published as Linked Open Data is what makes this possible to accomplish, although with good interface design that will be more or less invisible to the digital archivist populating the CMS.
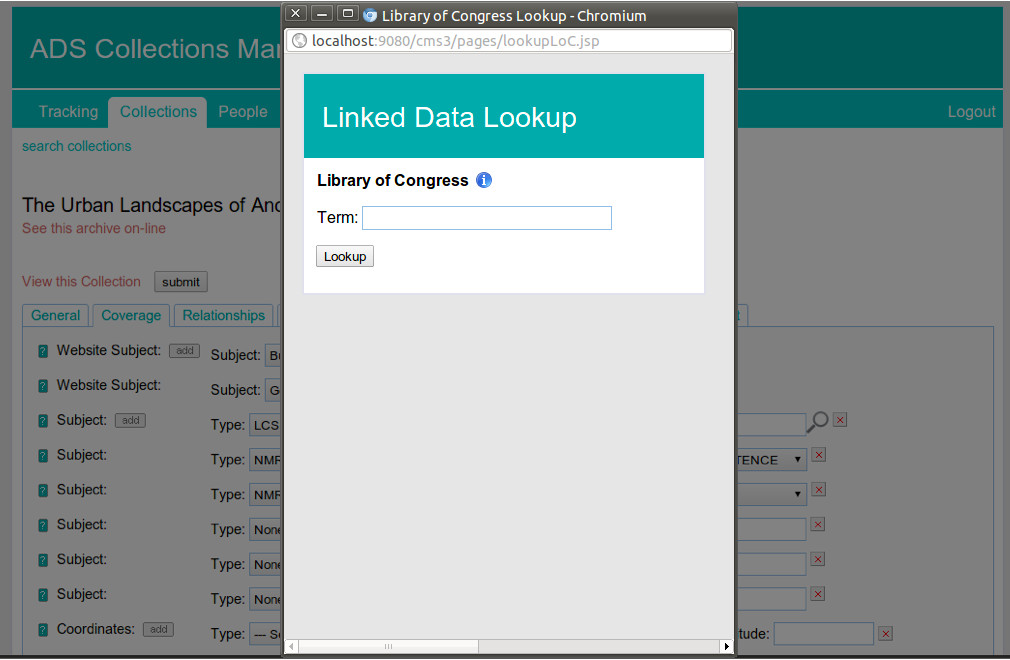
In summary, the SENESCHAL outputs finally offer the ADS the ability to easily and accurately align our archive metadata. Previously managing and interacting with the EH Thesauri required lots of manual intervention, but by SKOSifying and publishing the thesauri as Linked Open Data we can now integrate the thesauri into our systems. Now when our digital archivists are working on archives they will be able to associate the proper thesauri term with the archive, rather than inserting free text. All of the relationships and hierarchy will also be immediately visible to them, decreasing the chance of selection errors. Beyond the advantage of the ADS being able to more accurately and consistently align our archive metadata, the users of the ADS will also benefit since we’ll be able to immediately publish useful and descriptive Linked Open Data for all of our archives. We had already started doing that, but without the main thesauri we use published as Linked Open Data the usefulness of our archive metadata was limited. This is no longer an issue thanks to the SENESCHAL outputs.


Great to see gradual interlinking of Linked Data resources – with regard to the interesting alignment work, I think it’s worth flagging that the output of automatic alignment needs human inspection for it to add real value; a 100% match on an individual term doesn’t necessarily mean it’s the correct concept to link to as terms can of course be ambiguous – there’s still some manual overview and quality control required.
It’s particularly true of place names – an example is http://data.archaeologydataservice.ac.uk/10.5284/1011330 which (currently) has a ‘coverage’ link to Amarna (in Morocco), where it should (I think) be Amarna in Egypt.
Previous indexing practice would presumably have been to index with both ‘Amarna’ and ‘Republic of Egypt’ to provide this disambiguation; this of course then also leads to the linked data having a ‘coverage’ of ‘Republic of Egypt’ for a small site, which is also a bit misleading!
Very good point Ceri! The automatic alignment was intended to only pick off the “easy wins” with regards to our CMS metadata, but even with very conservative conditions that wasn’t perfect (as your Amarna example highlights). I was also only using a single placename in the automatic lookups and not comparing other terms in the hierarchy to provide disambiguation, something i’ll definitely add to any future implementations.
The reason we intend to integrate the lookup classes into our CMS is for exactly what you have pointed out, accurate alignment can really only be done by a human. The potential for ambiguity with the vocabularies used in SENESCHAL is also high, so it will be key to embed the alignment process in existing workflows. These lookup classes will also be integrated into our OASIS and ADSeasy systems, so with some clever interface design we will be able to offer this to external users of our systems.