An online presence is just the tip of the ADS iceberg, but as such we still rely on search engines to direct traffic to our archived datasets and web content. Search engines are not the only way people find their way to the ADS, as we provide metadata to many aggregators and portals via OAI-PMH and SOAP web services such as the Heritage Gateway, Europeana, Thomson Reuters Data Citation Index, Keepers Registry, NERC Data Catalogue Service, and MEDIN Data Discovery Portal to name a few. Even with all of those outlets to discover ADS content, a fair share of users still come via a good ol’ Google type-and-pray search. We are referrer agnostic at the ADS, and don’t really care how people discover our resources… so long as it doesn’t circumvent our Terms & Conditions (T&C’s).
Search engines are not the only way people find their way to the ADS, as we provide metadata to many aggregators and portals via OAI-PMH and SOAP web services such as the Heritage Gateway, Europeana, Thomson Reuters Data Citation Index, Keepers Registry, NERC Data Catalogue Service, and MEDIN Data Discovery Portal to name a few. Even with all of those outlets to discover ADS content, a fair share of users still come via a good ol’ Google type-and-pray search. We are referrer agnostic at the ADS, and don’t really care how people discover our resources… so long as it doesn’t circumvent our Terms & Conditions (T&C’s).
A side note on the the ADS T&C’s, they were drafted in the early days of the web, well before the advent of the Creative Commons or other similar licencing models, and were designed to credit the creators of the data while protecting their intellectual property from uncompensated resale. It doesn’t cost anything to access or use data from the ADS as long as you agree to the ADS T&C’s, which is usually done by clicking an “Agree” button when accessing data for the first time. While at times mildly annoying, we are all lucky that the original proposal from the AHDS lawyers (requiring a signed letter from each user wanting to access ADS data…… really!) was dismissed and the infinitely more convenient click-agreement prevailed. Ultimately our T&C’s were borne out of a belief in Open Access, which has been a core tenet of the ADS philosophy since its beginnings in 1996.
From the first incarnation of the ADS website, the T&C’s have always been part of a simple session-based mechanism protecting pages containing download links. This was fine for our web pages, but our underlying file system data was not protected. This technically meant our T&C’s could be circumvented by direct access to those files, whether that be direct links to images from other websites or direct links to PDFs via Google. The direct access from other websites was of minor practical concern, however the amount of direct access requests coming from Google was leading us to question whether we could keep our data behind our T&C’s while still enabling Google to index us. In addition to circumventing our T&C’s, directly accessing content from the ADS was also bypassing our analytics software, Piwik, which meant we didn’t know how many people were discovering and using our PDFs via search engines. Our final concern with direct access was the loss of the “ADS context” for our PDFs, since we would often get help desk requests from confused users who stumbled upon our PDFs from a Google search and only had our archaeologydataservice.ac.uk domain to associate that content with.
The solution we came up with was what we called the Direct Access Filter. This is effectively a servlet living in our Java Web Application that determines if a file has been requested, who has made the request (a search bot or a user) and if a session already exists. If the request was made by a bot, we let the request straight through so the content can be indexed. However if the Direct Access Filter identifies the request as coming from a user, it checks if a session has already been created and if not it re-routes the request via the T&C’s to ensure compliance. To prevent the need to manually change any href’s in our pages, we also added a redirect at the Apache domain level to force all requests for files via our Direct Access Filter servlet.
This kind of behaviour is often referred to as “cloaking”, which is something that Google and other search engines usually look down upon. However, as long as cloaking isn’t used with the intention of deceiving the user (ie. getting a search engine to index a grey literature report but then sending users to a Rick Astley video) it is usually an accepted practice. Google even engages in “cloaking” for location based content, such as redirecting google.com requests in the UK to google.co.uk.
In trying to balance our indexability while preventing direct access we naturally went through a lot of tweaking of the Direct Access Filter. A really useful tool in understanding how our site appears to Google is its Webmaster Tools. After we implemented the Direct Access Filter we noticed almost immediately that our Google crawl dropped off precipitously.
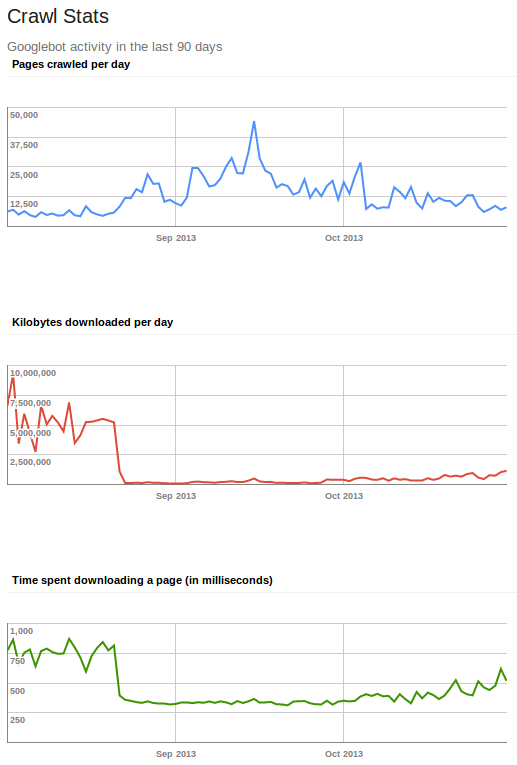
We looked at the Kb downloaded per day dropping off overnight (from an average of 5,000 Mb to 85 Mb) as indication that Direct Access Filter was blocking Google from indexing our PDFs, since our HTML alone couldn’t come close to offering Google Gigabytes of content to crawl. After some subsequent tweaks to the Direct Access Filter we began to see a little more content being exposed to Google, but it still wasn’t quite right as you only see a very minor increase in the amount of data the crawler is downloading per day. Once we finally nailed down the Direct Access Filter rules, we saw an immediate increase in the amount of data the Google crawler was downloading per day.
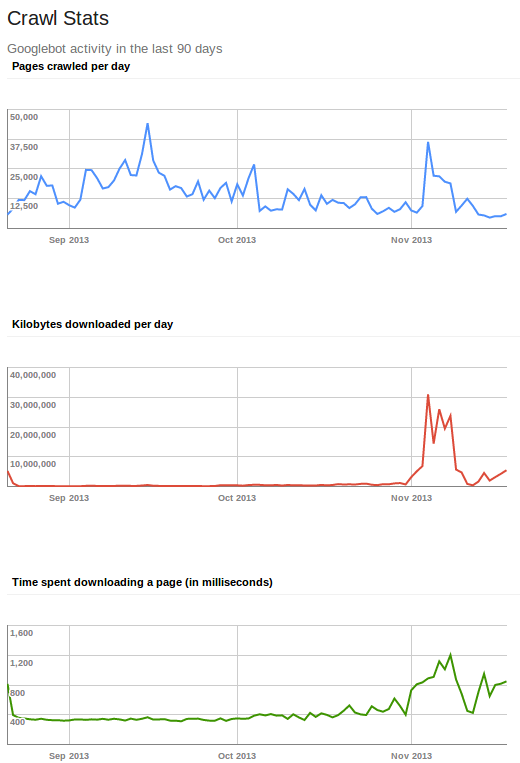
Having Google index our PDFs again is great, but simple searches for “Medieval Pottery” wasn’t returning any of our PDFs, even after clicking through pages of results. The Google indexing process takes time, so we don’t expect a lot of our PDFs to be in the top 10 results for broad search terms such as “Medieval Pottery”. However, by using Google Search Operators we could focus a Google query on our content to confirm that Google has indeed been re-indexing our PDFs. The following query in a Google search field:![]()
forces a search within our domain and for PDF files on the keyword “Medieval Pottery”. This returns 416 results, which is what we’d expect to get from that kind of query. Whether a generic search for “Medieval Pottery” will ever return a PDF from the ADS in the first results page is dependant upon the magical and somewhat mysterious Google Search Algorithim and what techniques it uses to rank its indexed results. We’re confident that more specific search queries (ie. grey literature titles or site names) will return ADS content eventually, but the discoverability of ADS content from those broad and generic archaeological terms will be dictated by the Google Search Algorithm and their time-scales (we’re not holding our breaths).
While going through the process of fine-tuning the Direct Access Filter, we also found some other very interesting things about how Google sees our site via their Webmaster Tool mentioned above. One useful facet of this tool is the keywords associated with our site within the Google Index. These are the terms that Google is associating with our site from its crawls (ie. how Google is interpreting our site). Unsurprisingly, the top term with the most significance is “archaeological”, which is a term that will be associated with pretty much every page and PDF in the ADS website. However the second most significant term is “doi”, which was not expected. I’d assume that something else is going on here to rank that so highly as a content keyword, but it could also be simply because the string “doi” is associated with every archive. Other terms in our top 20 of content keywords are typically archaeological terms such as “trench”, “pottery”, “excavation”, “medieval”, “fill”, “pit” and “ditch”, but we also have more generic terms such as “east”, “west”, “north” and “south” (reinforcing the spatial nature of most archaeological data) in our top 20.
Another interesting facet of the Webmaster Tool was the Search Queries that are returning ADS results and what the average rank for those queries are (ie. how users are finding our site). This provides interesting insights into what people are searching for and what ADS content is being returned. The obvious searches like “archaeology data service”, “ads” and “roman amphora” all bring a lot of traffic to our website. Another useful metric is the average position our content ends up in the results for specific queries. As expected, searching for “archaeology data service” or “archaeological data service” or “ads” gives our content an average position of 1.0 (or the top result). Search terms related to some of our popular collections also average as the top result:
- defence of britain
- discovery and excavation in scotland
- englands rock art
- cba research reports
- berkshire archaeological journal
The high average position for these search terms may be the result of smaller online presences for those resources, as we have archives for Stonehenge and Clifford’s Tower but our content is completely over shadowed in Google by much larger online presences elsewhere. Some more noteworthy or unusual queries that we have a high average position for are below (with the average position in brackets):
- to what extent should we invest in archaeology, and why? [1.0]
- proceedings of the society of antiquaries of scotland [1.1]
- what is midland purple [1.4]
- castelporziano [1.3]
- alan vince [2.0]
- medieval glasgow [2.1]
- archaeology database [2.3]
- slipper baths lincoln [2.8]
- صخره بریمهام, انگلستان [3.0]
- armbog [3.0]
- survey to win [3.0]
- data archaeology [3.0]
- girdle hanger [3.0]
- scottish archaeology [3.3]
These positions will vary depending on who is searching for it and where they are making the search, as the Google Search Algorithm takes into account a number of known and unknown factors to tailor your search results. Some other unusual search terms that were listed by Webmaster Tools as having ADS results were things like “i love her”, “picture description english”, and “cornwall .gov”, but none of these were listed in the top 50 when i searched for them myself.
Implementing the Direct Access Filter has been on our to-do list for a while, and finally having it running does tidy a few things up for the ADS regarding adherence to our T&C’s and capturing better usage stats. One unexpected result was a better understanding of how we expose ourselves to Google, and in turn get better analytics information on our sites usage. With the Direct Access Filter in place (and properly tuned) for a month now, we have finally been able to better understand how people are coming to our site (since before the Direct Access Filter we missed a lot of the direct access from Google). A breakdown of referrers in Piwik for the last month (Nov 2013) shows the following:
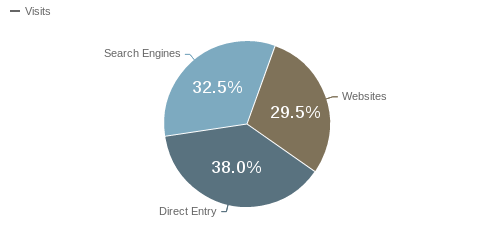
with “Direct Entry” referring to ADS urls typed into the address bar or bookmarks (not the same as direct access I talk about above). That shows a pretty even distribution of entry points into the ADS, and comparing this to our pre-Direct-Access-Filter stats, our Search Engine entries have increased about 5% after the implementation of the Direct Access Filter. Over time that may increase even more as the Google index matures, but for now we’re happy we’ve achieved a good balance between our search engine exposure and respecting our T&C’s.