The ADS is an accredited digital repository and data that’s deposited with us is available open access via our archives or library but what actually happens to the data?
First off, it depends on how the data is deposited with us and what the end state of the data will be but it also depends on what kind of data has been deposited.
, Online via ADS-easy (small/medium datasets), Directly via an ADS digital archivist (large/custom datasets)")
The OASIS form allows archaeological and heritage practitioners to provide information about their investigations to local authorities and securely archive it within our Grey Literature Library for free. ADS-easy is a faster way to deposit small to medium-sized project archives and associated metadata directly into the ADS repository. Please note, only certain data types can be submitted through ADS-easy, while file size limits and file number restrictions are in place. The ADS-easy help pages have a step-by-step guide to using ADS-easy. The first 150 images are included in the startup fee and all other files have an associated fee. For larger projects, a variety of data delivery methods can be accommodated including CD-ROM, portable hard drive, email and Cloud services. Data should be accessible without a password or other security features or restrictions enabled. We accept some forms of compressed data (i.e., .zip, .gz).Each deposit method has varying amounts of manual checks done to the data by archivists with large deposits requiring the most checks and OASIS requiring the least.
For reports that have been deposited via OASIS, minimal additional checks are done by archivists into the contents of the reports as the reports themselves are checked via OASIS both programmatically and through an approval process. Similarly, ADS-easy has a number of checks built into the system but it then becomes the archivist’s job to check the actual data submitted. Large datasets on the other hand require nearly all checks to be completed by an archivist.
But what are these ‘checks’?
Because of the way that we disseminate the data, every file that is deposited with us needs to follow certain rules about file naming in addition to specific rules that each data type receives. For example, we can’t accept any files that have any non-alphanumeric characters in the name with – and _ being exceptions to the rule. Let me show you:
H3!!0 !’m [email protected] would not be accepted but Hello-I_am_Teagan.jpg would be.
Beyond that, every file should be able to be opened and should be in a condition fit to be disseminated which largely means it should ideally not have something like ‘FIX THIS!!!!!!’ still within the document/image/model/etc. It should have good metadata as well.
When these checks are completed, there is one final check that happens before the processing begins.
Everything that’s deposited with us is processed based primarily on what the data is. Is this a csv a spreadsheet, database, or geophysics? Knowing this changes what file formats are accepted and how we’ll preserve it.
Let’s take a look at raster images.
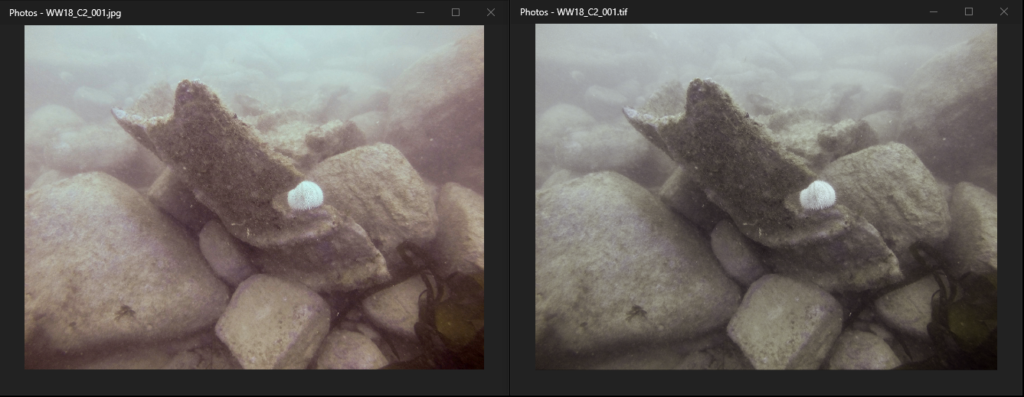
Below we have two versions of the same image. The left is a jpg and the right is a tif (though the image itself is actually a png with both of these within it). But to those unfamiliar with the hip, happening world of archiving, that previous sentence may have made absolutely no sense. So allow me to explain.

The above image was taken on as a part of the Wheel Wreck Investigation 2018 and was deposited as a tif. A tif, or Tagged Image Format, is an uncompressed image format. As you can see, the tif shows a better rendering of the image both in colouration and clarity but that comes at the cost of the size of the image being 70 times greater than the jpg image. Additionally, social media doesn’t typically support tif as a file format so you can’t share it. Bit rude, but what can you do?
As such, we disseminate all of our images as a jpeg or png (the difference of which is for a different discussion) and preserve a copy of the images as a tif. As we were given a tif in this instance, we migrated it to a jpg which is a commonly used format for dissemination.
Similar changes will be made for different data types. For instance, presently a vector drawing deposited as a dwg would be preserved as a dwg and disseminated as a dwg and a dxf and a pdf (all would also be updated to the current version at the same time). Alternatively, geophysics data would be preserved as it was deposited but disseminated as a zipped version. Meanwhile GIS data would be preserved as Geography Markup Language (GML) and disseminated as a shapefile. All of these changes have specific reasons behind them to do with widespread use, proprietary software, stability, and more.
Now, you may be questioning my specific phrasing of preservation version and dissemination version and how that relates to the archiving. Well let me take you into the beautiful world of our repository operations.
The preservation of data is more than just making sure that it fits specific criteria or that it’s been migrated according to the current file format. These steps are just the beginning of what the ADS does with the data.
Below is an excerpt from our Repository Operations (Version 6.0) and it shows how the preservation and dissemination format feed into a collection as a whole.
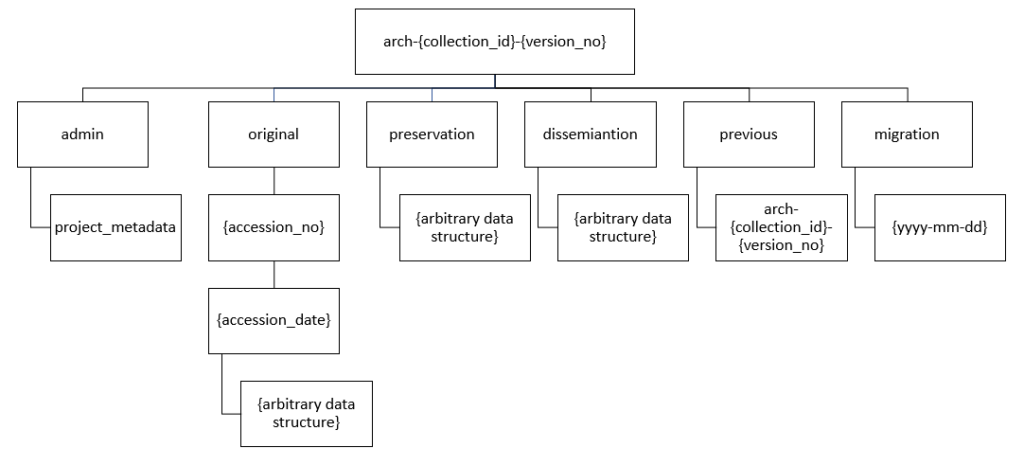
If the collection has had pervious versions or a migration of the data within it preformed, then it will also have folders reflecting those changes.
When data is deposited, it is deposited as a part of a collection. OASIS reports make up report series on our library but they are stored the same way as data deposited from ADS-easy or as a part of a larger collection. These collections are given unique identifiers and from these the data is stored in different folders which correspond to what the folder holds.
To explain further, each collection will have an admin folder to hold licences, correspondence, and a deposit receipt which holds a list of all the data that was originally deposited with us including it’s checksum.
From there, there is a folder containing the data that was deposited in its original form, organised by both accession number/date and a further arbitrary data structure that is unique to the collection. This data is rarely touched by the archivist and serves as a copy of the data as it was deposited.
The data that is within the original folder is migrated to a preservation and/or dissemination format as described previously.
It doesn’t stop there, however. Some collections are updated with a newer version of the data. In those cases, the old data is preserved in a previous folder and the new is organised as above.
But even then, the archiving doesn’t stop there. All of our file formats are monitored to ensure that they are still able to be opened and used. In certain instances, that can mean that all past data deposited and preserved in a certain format will need to be migrated to a newer version, which actually happened with some of our 2 and 3D datasets. In that case, the migrated data is saved within a migration folder.
Even after all of that, we still do more. All of our data is saved in three different locations on two different mediums to ensure that even if something happened to one of the locations where the data is physically stored, all of our collections would still be preserved.
Hopefully this helps explain some of the mystery behind the ADS and what happens to data between deposit and which it becomes accessible on our website. If your confused on how to deposit or what kind of interfaces we offer for dissemination, our Guidelines for Depositors hopefully explains all of that.