
No preservation format is perfect. While physical mediums such as paper can last centuries under proper conditions, it is that qualifier that is key to its longevity. Everyone has seen what can happen to paper when it gets wet. Similarly, there are many horror stories of corrupted files that have helped create sceptics for using digital preservation over physical preservation.
We have had 4000+ years to develop strategies to conserve the ‘written’ word and less then 50 for methodologies to preserve digital data. However, as long as digital data is properly cared for, there is no reason that it too cannot last just as long.
There are two types of digital data; born digital which is data that has never been in a physical format or digitised data which was originally a physical before begin converted. Both types of face similar problems and today I‘m going to talk about one of the more hidden killers of digital data: data degradation.

The above post by xkcd is one of my favourite examples of data degradation. Data degradation is the accumulation of errors within a file, typically by external factors (virus, software issues, etc.). If these errors are non-critical the file can still be opened or viewed, but as you can see above, a new failure has been introduced with each save of the image, which has decreased the quality of the image as a whole.
This problem can be compounded by the ‘lossy’ compression algorithm that is used in common image files which means that simply opening the file and saving it re-compresses the image which can introduce errors or augment existing ones. This particular type of degradation is also called generation loss. It is important to note, however, that this issue can exit in other formats, but issues with images can be more… visible.

It‘s not just saving that introduces errors into a file. Manipulating a file without the proper software can also introduce these errors. The above image by Jim Salter shows the continuing degradation of a JPEG. The image of a child becomes increasingly pixelated and the colours are darkened as an additional bit is flipped in the three subsequent images. While this error is intentional, it shows how badly small amounts of damage to a file can degrade the visual presentation of the JPEG.
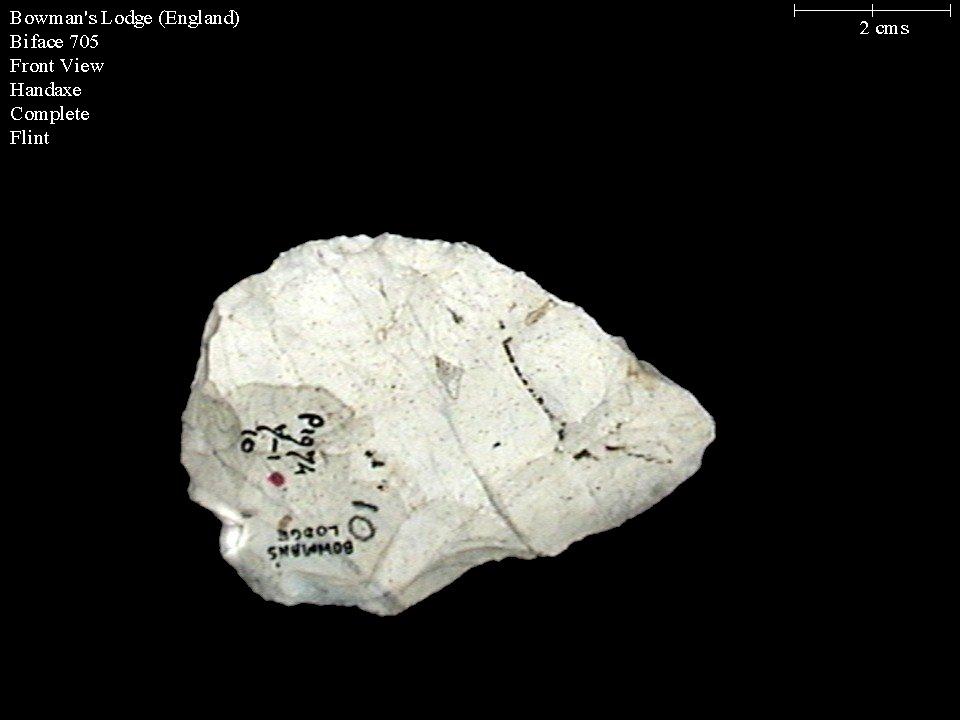
At the ADS, we accept data through a number of different mediums: web transfer, USB, CD, etc. Each of these different mediums comes with a different set of risks both physical (i.e., CD oxidation) and digital (i.e., file corruption). The above images from University of Southampton are both of the same biface. We were sent the clean image that you see on the right via a CD but when the image was transferred from the CD to a computer, it became corrupted as can be seen on the left where the top lines of the images began to repeat and turn into what almost looks like police tape before fading to green.
There are ways to mitigate this risk. We employ file transfer protocols, deposit receipts (checksum particularly), manually check of data, employ specific preservation formats, etc., in order to minimise data loss during the transfer process. Of these, the checksums of the data are of particular importance and are routinely checked in order to ensure that the data is not just left to rot.
Checksums are a sequence of numbers and letters such as the following, 1a9ccb1c2805b2eb3851aada468e4e4a, which unique to a piece of data. This sequence is unique enough that if you have two identical files and you make the same change to each of these files and save them, they will have two different checksums. This sensitivity is what allows it to be a key factor in determining if a file begins to change after it has been preserved.
The examples I talked about today are just some of the ways a file can corrupt. With archaeological data, we typically one get once chance to preserve what was found. The preservation process doesn’t stop when you hit save on a computer and the importance of preserving that data is why we were created and continue to exist today.


{kind=link}