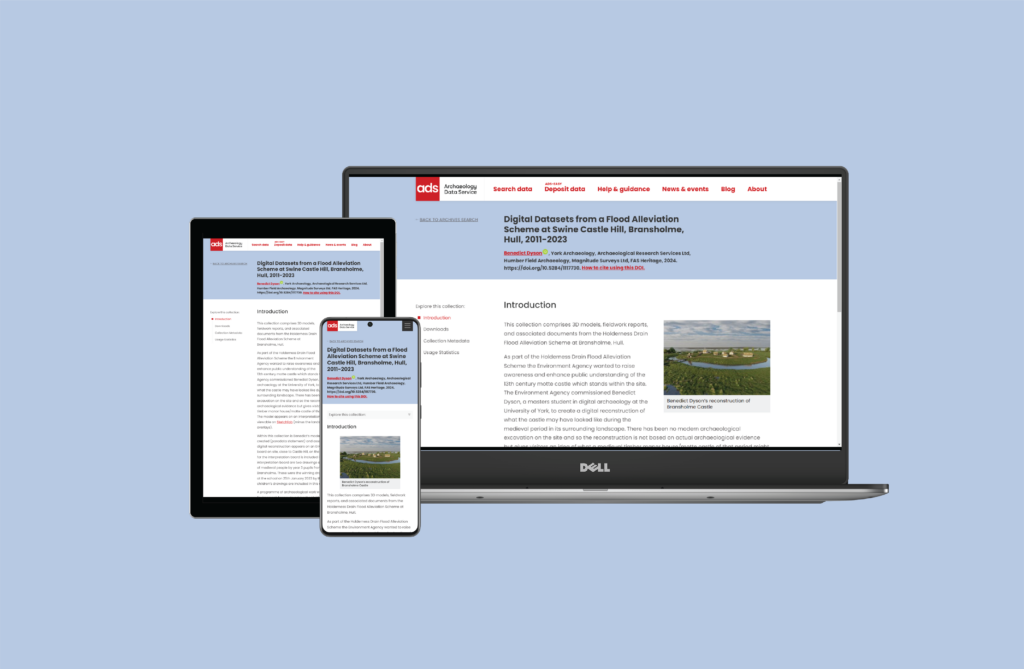
As we announced back in March, the ADS is due to launch a series of new features for the ADS Archives templates that provide an accessible and intuitive user experience and now more closely reflect FAIR data requirements. Below, we detail some of the motivations behind these new web templates, what has changed and why, and what we plan on implementing in future updates.
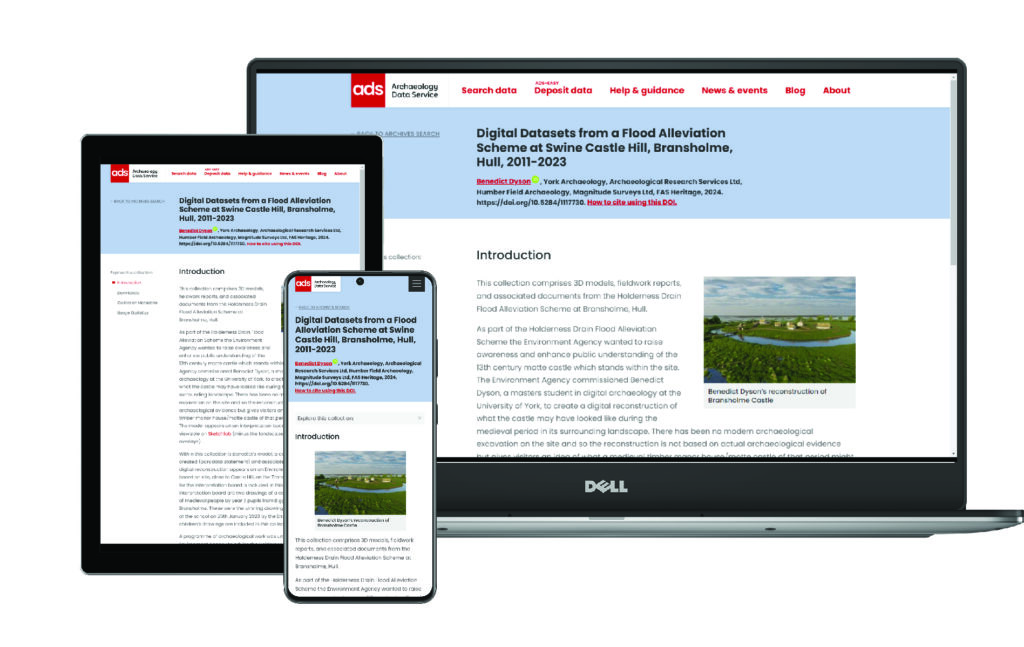
What are the templates?
Quite simply the templates are the higher-level code that is used for all modern Collections. Rather than hand-write each page (as we did in the old days), the archivist working on a Collection selects which code template is relevant to the task in hand. The Collections Management System (or CMS, a database with web interface used by archivists) populates everything you see on the screen without the need for an archivist to interact with the source code. The advantage of this is speed, consistency, and most importantly a code base that can be updated or migrated with minimum fuss.
We’ve had the current templates for several years, with periodic tweaks to the old code to build in more functionality on a case by-case basis. However this recent piece of work, implemented by web developer Adam Fox and guided by the domain level expertise of digital archivists Kieron Niven and Jenny O’Brien, is a bigger overhaul that has allowed us the opportunity to build in many functional improvements that have been on the agenda for some time.
What has changed, and why?
Accessible and Mobile Friendly
The Collections part of the ADS – by which I mean the pages that present archived data and metadata – is a separate entity to the main ADS website. When the new website was launched we were well aware that other parts of the ADS also needed to change so as to meet accessibility requirements, but also to keep a consistent look and feel throughout all our applications. Thanks to the skill of developer Adam Fox the templates now follow the ‘house-style’ and work across devices and screen sizes, and meets our strategy to make sure that every part of the ADS is accessible.
Collection Metadata as the new landing page
The first major functional change is that the default landing page for all new archives is the re-styled collection metadata page. Previously a user would be directed to a page with introductory text and an image, with key administrative metadata such as creator and copyright holder split between the header and left-hand menu, with meaning often not clearly marked but left to the user to interpret from images such as logos. By putting the Collection metadata as the first thing a user sees it is hoped that people can better appraise content (both in terms of files available, subject matter, geographic location). The formatting of the page has been restyled to better meet with the FAIR recommendations, while at the same time presenting the metadata in a manner that we hope is simple and clear, including adding extra details such as project identifiers and relations.
Object metadata
Historically object metadata – the information which describes the files within the archive – has been collected via a series of templates filled in by depositors and/or collected via online forms in ADS-Easy and OASIS. This metadata has been presented to the user as files to download, and with some values put on the screen. These values come from a database known as the Object Metadata System (OMS), and its long been our ambition to ensure that core metadata for all files goes into this schema. This is essential for data management (knowing what we have!), but also a boon for users who want to understand the contents of a file without having to always download additional files.
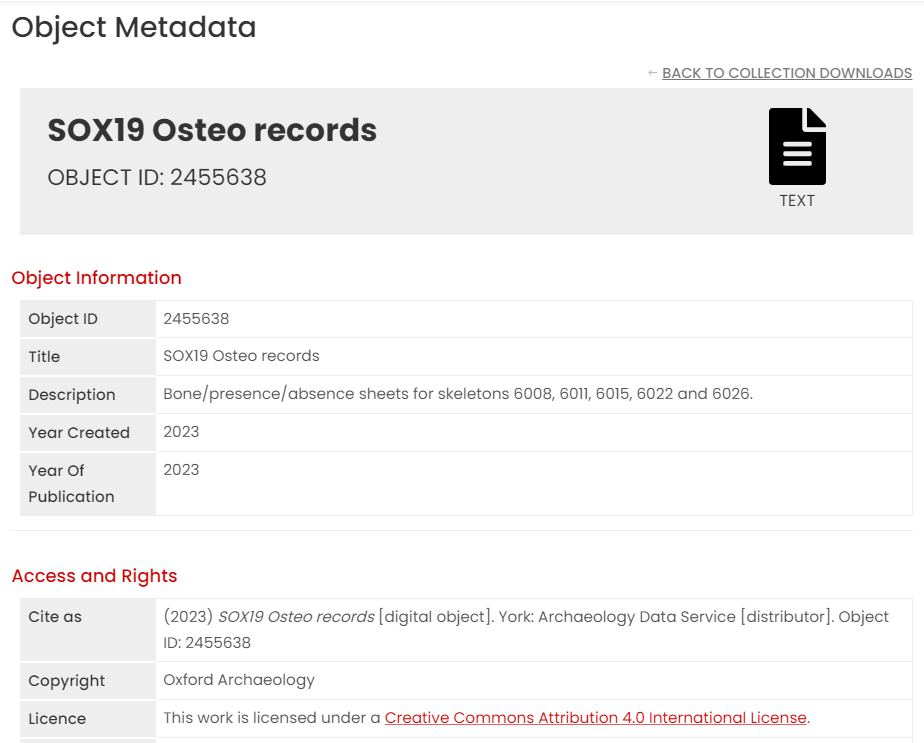
The recent update has taken a big step towards unleashing the power of the OMS; technical, administrative and thematic metadata is now displayed on the screen and some data types have preview visualisations to allow a user to better appraise what the data looks like before committing to a download.
These object metadata pages, such as Object 2455635, use a unique identifier per object. Thus It’s easy to use these links as landing pages for future developments in search interfaces. For example, a search interface that allows a user to cross-search all ADS images or 3D models, or indeed everything that we hold. This granular search is still some way off, and requires a bit more thinking about the Object URIs (Uniform Resource Identifier) and “Persistence”…
It’s important to note that the original metadata compiled by the depositor is still available to download with the files, with links between a data object and a (meta)data object recorded within the database.
Image Search
Images are the most common form of data deposited, often with large numbers per archive. Depositors fill in metadata templates with keywords denoting subject matter. As these keywords are now in the OMS (see above) we’ve used them to build a simple filter search. In this example a user can use these tags to browse by different feature/context types such as ‘skeleton’ and ‘tree throw’.
Commonly compiled from the aforementioned metadata spreadsheets these keywords aren’t controlled vocabularies, but represent the classification (or ‘tagging’) done by the original data creators. Although we’ve always recommended people use controlled vocabularies, it’s often incredibly hard to implement for large volumes of data compiled manually and outside of web forms, and almost impossible for us to check and correct against the high volume of data we receive.
The original metadata is therefore presented ‘warts and all’, and represents a very simple way for a user to try and filter. We don’t want to leave it there however, and we have plans for how we can map these tags programmatically onto the controlled terminologies we all know and love, and potentially others as and when they become requirements of our designated community.
Future plans
From this point on all new Collections will be released in the new templates, which includes many projects we’ve been working on over the Winter and early Spring. A few older archives have also been migrated into the new style as a test for compatibility. This still leaves most of our collections, and certain pages within the archives application such as the archives search and collections history in the older styles. Once the dust has settled on this update we will begin migrating projects and pages into the new style, so you will notice your favourite ADS archives changing in appearance. It’s always important to note that no archives are being turned off, and data will still be available even from an ‘old style’ interface until we’re ready to move it.
In terms of the templates themselves, although other priorities and projects dictate that we stop work for now, we’re scheduling periodic updates to meet internal requirements and the feedback from users. The next planned updates include, but are not limited to:
- Allowing metadata pages to be exported.
- Inclusion of extra metadata fields, including those recorded in OASIS.
- An export png button for web maps.
- Reformatting the way links to OASIS reports in the Library are presented.
- Display of contextual information for where data has been deposited with Informed consent, and flags/alerts for sensitive data.
Thoughts or comments?
We are always looking for ways to improve our resources and the advice that we provide. We are interested in hearing your thoughts about these changes and our future plans. If you have any comments or questions please get in touch with us via the ADS helpdesk ([email protected]). You can also contact us by sending a message through one of our social media channels (Twitter, Facebook, Instagram, LinkedIn).