As it’s World Digital Preservation Day I thought I’d finished the following blog about our work with managing the digital objects within our collection. Like most of my blogs (including the much awaited sequel to Space is the Place) these often languish for a while awaiting a final burst of input. To celebrate WDPD 2018, here we go….
I half-heartedly apologise for the self indulgent and title to this blog, which most readers will know is taken from Rutger Hauer’s speech in the film Bladerunner (apparently he improvised). Aside from being an unashamed lover of the original film, like Roy Batty in the famous rooftop finale I’ve recently been prone to reflection on the events I’ve witnessed [at the ADS] over the last few years. In all honesty these aren’t quite on a par with “Attack ships on fire off the shoulder of Orion”, but perhaps as impressive in their own little way.
This reflection isn’t prompted by any impending doom – that I’m aware of – but rather that the some of my recent work has been looking at the work the ADS has done in the context of the last two decades, for example looking at the history of OASIS as we move further into the redevelopment project, and revisiting the quantities and types of data we store as we find we’re rapidly filling up file servers. Along with this is a sudden realisation that after so long here I have become part of the furniture (I’ll let the reader decide which part!). However as colleagues inevitably leave – and although we do take the utmost care to document decisions (meeting minutes, copies of old procedural documents etc) the institutional memory sometimes becomes somewhat blurred, even taking on mythical status: “We’ve always done it like that”, “That never worked because…”, “So-and-so was working on that when they left”, “A million pounds” and so on.
Saving uploading Julian’s consciousness to an AI, which even with our best efforts we’re still some way off perfecting, there’s a danger of much of this internal history becoming lost (like tears in the rain). Over the past few years I’ve quite enjoyed talking – mainly to peers within the wider Digital Preservation community – about issues and problems/successes at the ADS. And just recently I gave a talk at CAA (UK) in Edinburgh about the twenty year journey of the ADS, from one of the 5 AHDS centres to a self-sustaining accredited digital archive. The talk itself didn’t have a particularly large audience, perhaps a result of the previous nights party (the conference as a whole was welcoming and well-organised) or the glittering papers in the parallel session, plus on this occasion I think I struggled to get 20 years of history into exactly 20 minutes!
The main thing I really wanted to communicate to people was quite how far the ADS have come technically and conceptually, from our beginnings in 1996, where we are now, and more importantly where we want to be. As a previous blog has covered in massive detail (WITH GRAPHS!) our holdings have grown considerably over the years, with associated problems in finding room to store things. Another issue as we surge past 2.5 million files is increasing the capacity for our users (and us!) to find things. As I showed an enraptured audience at CAA we’ve come along way from 2006 (when I joined) when we were running 2 or 3 physical servers, to the present day where we have a dispersed system of nearly 40 virtual machines with a range of software, which in turn support a large array of tools, applications and services that underpin our website(s), and the flows of data we provide to third parties.

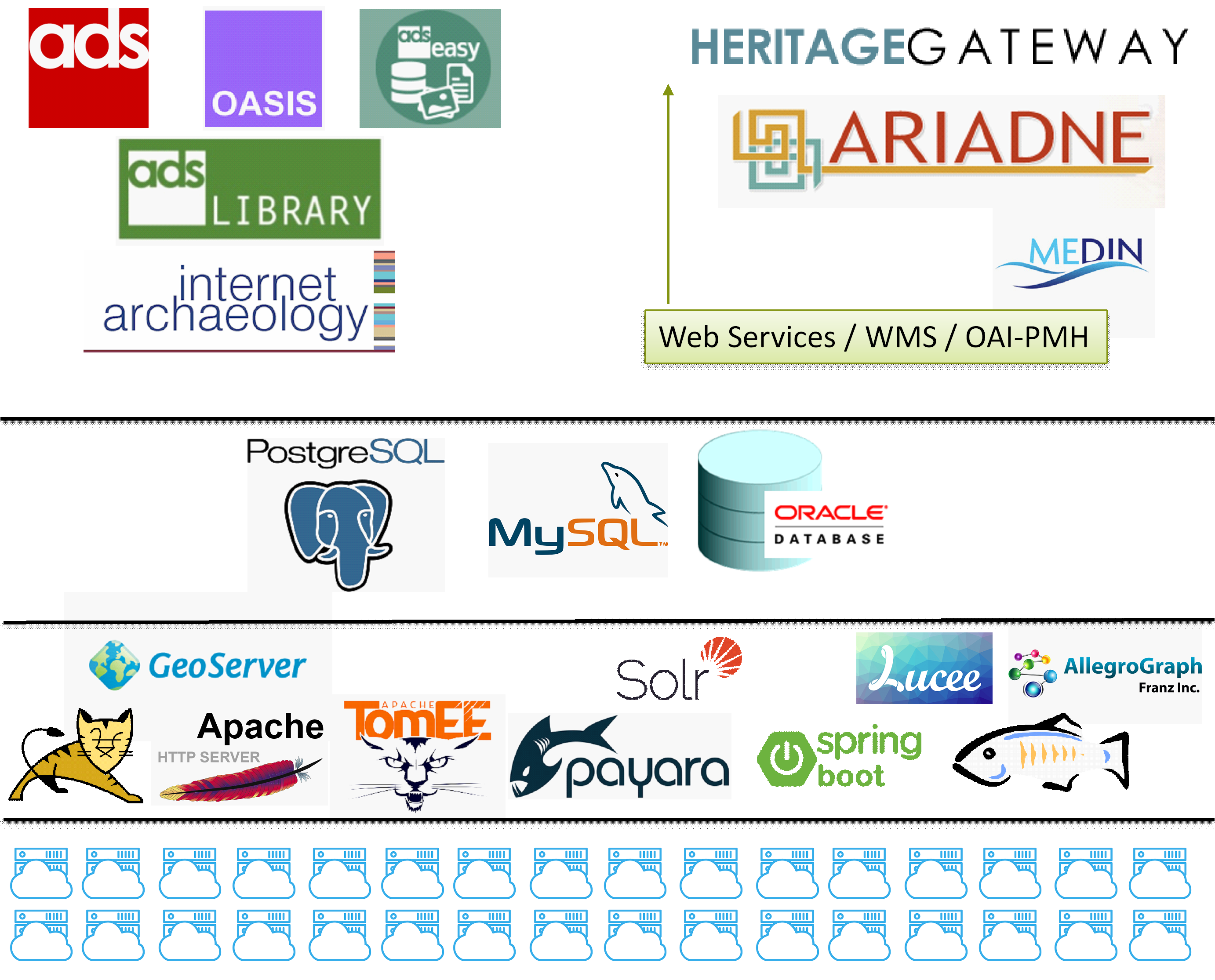
I always think this is an unseen part – to many outsiders – of what the ADS do, and along with the procedures we have for actually being an archive there’s a whole lot of work going on underneath what we make visible to our users. In the talk to CAA I used the common analogy of a swan, what you see is the website, what you don’t see are the feet paddling away underneath. This doesn’t detract from the website of course, a commitment to providing access to data has always been a fundamental part of what and who we are. It’s as frustrating to us as to a user when someone can’t find what they’re looking for, especially when they know it exists. Which is why it is interesting (and I really think it is) to look at how we manage our data, and to make the ‘ADS Swan’ as efficient as possible.
For example, back in the old days (2006) interfaces to data were effectively hard coded into web-pages using the ColdFusion platform (CFML) as an interface between the XHTML and underlying file server and database. This was ok in its way, although still required someone to either code in links to file, generate file listings in page (or via separate scripts or commands). A common source of many broken links of this era is simply human error in generating these lists and replicating them in the web-page.
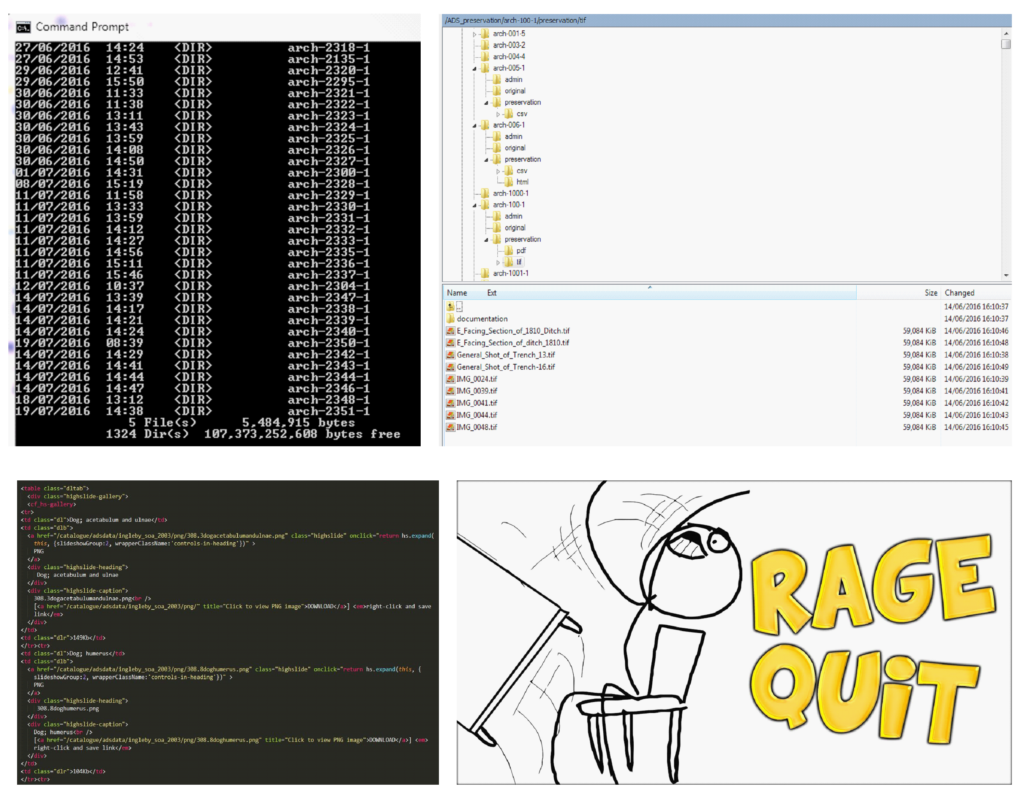
Of course, even at the time my colleagues were aware that this was not the most efficient way we could work, and even the functions of ColdFusion (and its successors OpenBlue Dragon and Lucee) that generated listings directly in the code were still reliant on someone actually setting which directory was needed and how to handle the results directly in the page. Not great for when we had to update things… There was also an issue of the information displayed in the page, effectively you came to an archive, scrolled through and were presented with descriptions that were often little more than the file-name. There was also the massive issue of a disconnect between the files and the interface, actual file-level metadata was only stored in the files (e.g. CSV) in the file store. Our Collections Management System (CMS) stored lots of information about the collection, and we know it had files in it, but not the details. Any fixing, updating, migrating, querying all had to be done by hand, which was fine when we only had a small number of collections but presented problems when scaling up. Effectively, we had to get our files (or objects/datastreams) into some sort of Digital Asset Management System. Cue project SWORD-ARM…
This project is probable deserving of its own essay, suffice to say we investigated using Fedora (Commons, as it later became) as a DAM for storing all the lovely rich technical and thematic metadata we collect, and perhaps most importantly had already collected (we already had several hundred collections of nearly a million files at this point). In short, an implementation of Fedora to suit our needs was deemed too complicated, and with too high a level of subsequent software development and maintenance for us to sustain. At that point -and again to our understanding and needs – if even deleting a record required issuing a ticket for our systems team (the magnificent Michael and prodigious Paul at that point), then we were onto a loser. For our needs, perhaps all we needed as a database and a programming language…
The heroes of this story were undoubtedly Paul Young, Jenny Mitcham, Jo Gilham and Ray Moore who between them created an extension to our existing CMS: the Object Management System (OMS). The OMS is really too big to explore in too much detail, but the design of it was based on three overarching principles:
- To manage our digital objects in-line with the PREMIS data model
- To store accurate and consistent technical file-metadata
- To store thematic metadata about the content (what does the file show/do?)
The ambition was, and still is, to have a situation where a user provides much of this information ready-formed courtesy of an application such as ADS-EASY or OASIS. But most importantly I believe (and for this blog not to derail into masses of detail) was the move towards an implementation of the semantic units as defined in PREMIS. To explain, consider the shapefiles below.
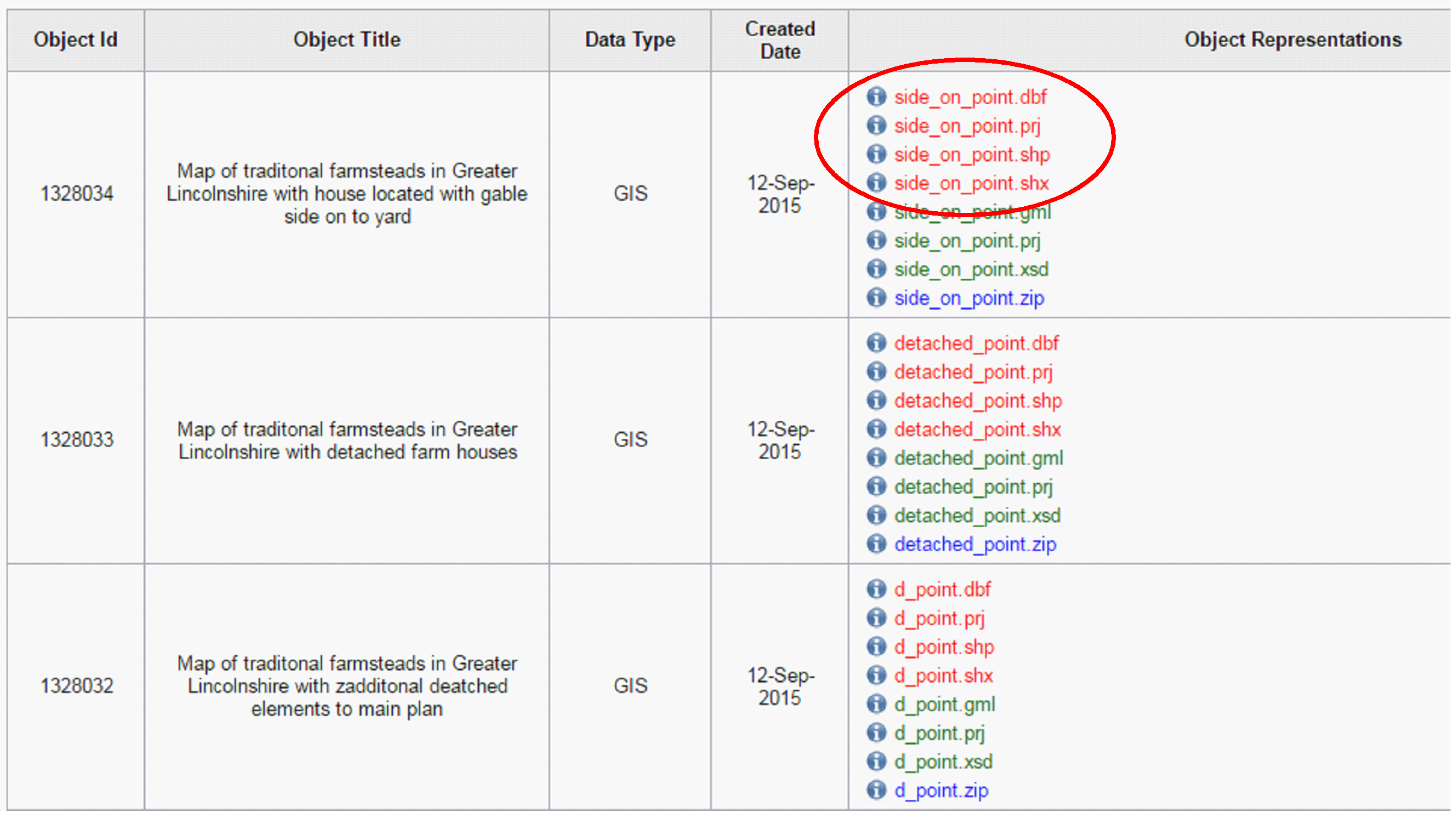
In our traditional way of doing things we just had a bunch of files on a server. Here, we have the files in the database but also a way of classifying and grouping them to explain what they are. So for example, a Shapefile has commonly used the dBase IV format (.dbf) for storing attributes; we also get .dbf as stand-alone databases. We need to know that this .dbf is part of a larger entity, and should only be “handled” as part of that entity. In this case a Shapefile is normalized to GML (3.2) for preservation, and zipped up for easy dissemination. All of these things are part of the same representation object, we need to keep them together however dispersed they are across servers, associate them with the correct metadata, and plan their future migration accordingly.
And of course this is where we can store all our lovely technical and thematic metadata. For example I know for any object:
- When it was created
- What software created it
- Who created it
- Who holds copyright
- Geographic location
- It’s subject (according to archaeological understanding)
- The file type – according to international standards of classification
- Its checksum
- Its content type
- If it’s part of a larger intellectual entity
And we’re close to also fully recording an objects life-cycle within our system
- When it was accessioned
- When it was normalized – and the details of this action
- When it was migrated
- If it was edited
- etc etc
I’ve deliberately over-simplified a very complicated process there as I’m running out of words. But suffice to say that the hard work many people (including current colleagues Jenny and Kieron) have put in on developing this system is nearing a stage where the benefits of all this are tantalizing close.
Now, readers from a Digital Preservation background will understand how that’s essential for how we need to work. The lay reader may well be thinking of the benefit to them. Put simply, this offers the chance to explore our objects having and independence away from their parent collections. For example, when working on the British Institute in Eastern Africa Image Archive (https://doi.org/10.5284/1038987) Ray built this specialised interface for cross-searching all the images. In this case all the searching is done on the metadata for the object representation, so for example:
http://archaeologydataservice.ac.uk/archives/view/object.cfm?object_id=1187702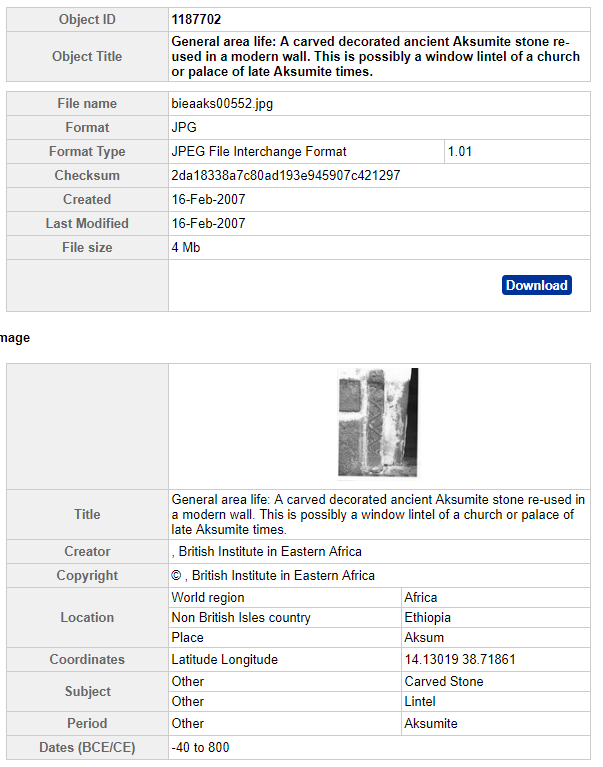
It’s not too much of a jump to see future versions of the ADS website look to incorporate cross-collection searching. Allowing people quick, intuitive access to the wealth of data we store and perhaps, a way to cite the object… Something to aim for in a sequel at least.
Anyway, as always if you’ve made it this far thanks for reading
Tim