
This is the first part of a (much delayed) series of blogs investigating the storage requirements of the ADS. This began way back in late 2016/early 2017 as we began to think about refreshing our off-site storage, and I asked myself the very simple question of “how much space do we need?”. As I write it’s evolving into a much wider study of historic trends in data deposition, and the effects of our current procedure + strategy on the size of our digital holdings. Aware that blogs are supposed to be accessible, I thought I’d break into smaller and more digestible chunks of commentary, and alot of time spent at Dusseldorf airport recently for ArchAIDE has meant I’ve been able to finish this piece.
——————-
Here at the ADS we take the long-term integrity and resilience of our data very seriously. Although what most people in archaeology know us for is the website and access to data, it’s the long term preservation of that data that underpins everything we do. The ADS endeavour to work within a framework conforming to the ISO (14721:2003) specification of a reference model for an Open Archival Information System (OAIS). As you can see in the much-used schematic reproduced below, under the terminologies and concepts used in the OAIS model ‘Archival Storage’ is right at the heart of the operation.
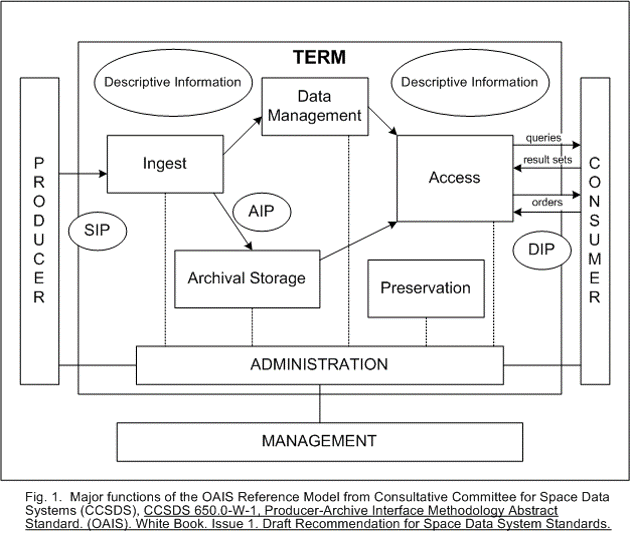
How we actually achieve this is actually a pretty complicated process, documented in our Preservation Policy; suffice to say it’s far more than simply copying files to a server! However, we shouldn’t discount storage space entirely. Even in the ‘Zettabyte Era’, where cloud-based storage is commonplace and people are used to streaming or downloading files that – 10 years ago – would have been viewed as prohibitive, we still need some sort of space on which to keep our archive.
At the moment we maintain multiple copies of data in order to facilitate disaster recovery – a common/necessary strategy for any organisation that wants to be seen as a Digital Archive rather than simply a place to keep files. Initially, all data is maintained on the main ADS production server maintained by the ITS at the University of York which is backed up via daily snapshot, with these snapshots stored for a month, and furthermore backed up onto tape for 3 months.
In addition to this, all our preservation data is synchronised once a week from the local copy in the University of York to a dedicated off site store, currently maintained in the machine room of the UK Data Archive at the University of Essex . This repository takes the form of a standalone server behind the University of Essex firewall. In the interests of security outside access to this server is via an encrypted SSH tunnel from nominated IP addresses. Data is further backed up to tape by the UKDA. Quite simply, if something disastrous happened here in York, our data would still be recoverable.
This system has served us well, however recently a very large archive (laser scanning) was deposited with us. Just in it’s original form it was just under a quarter of the size of all our other archives combined, and almost filled up the available server space at York and Essex. In the short term, getting access to more space is not a problem as we’re lucky to be working with very helpful colleagues within both organisations. Longer-term however I think it’s unrealistic to simply keep on asking for more space at ad-hoc intervals, and goes into a wider debate over the merits of cloud-based solutions (such as Amazon) versus procuring traditional physical storage space (i.e. servers) with a third party. However I’ll save that dilemma for another blog!
However, regardless of which strategy we use in the future, for business reasons (i.e any storage with a third party will cost money) it would be good to be able to begin to predict or understand:
- how much data we may receive in the future;
- how size varies according to the contents of the deposit ;
- the impact of our collections policy (i.e. how we store the data);
- the effect of our normalisation and migration strategy.
Thus was the genesis of this blog….
We haven’t always had the capacity to ask these questions. Traditionally we never held information about the files themselves in any kind of database, and any kind of overview was produced via home brew scripts or command-line tools. In 2008 an abortive attempt to launch an “ADS Big Table” which held basic details on file type, location and size was scuppered by the difficulties in importing data by hand (my entry of “Comma Seperated Values” [sic] was a culprit). However we took a great leap forward with the 3rd iteration of our Collections Management System which incorporated a schema to record technical file-level for every file we hold, and an application to generate and import this information automatically. As an aside, reaching this point required a great deal of work (thanks Paul!).
As well as aiding management of files (e.g. “where are all our DXF files?”), this means we can run some pretty gnarly queries against the database. For starters, I wanted to see how many deposits of data (Accessions) we received every year, and how big these were:
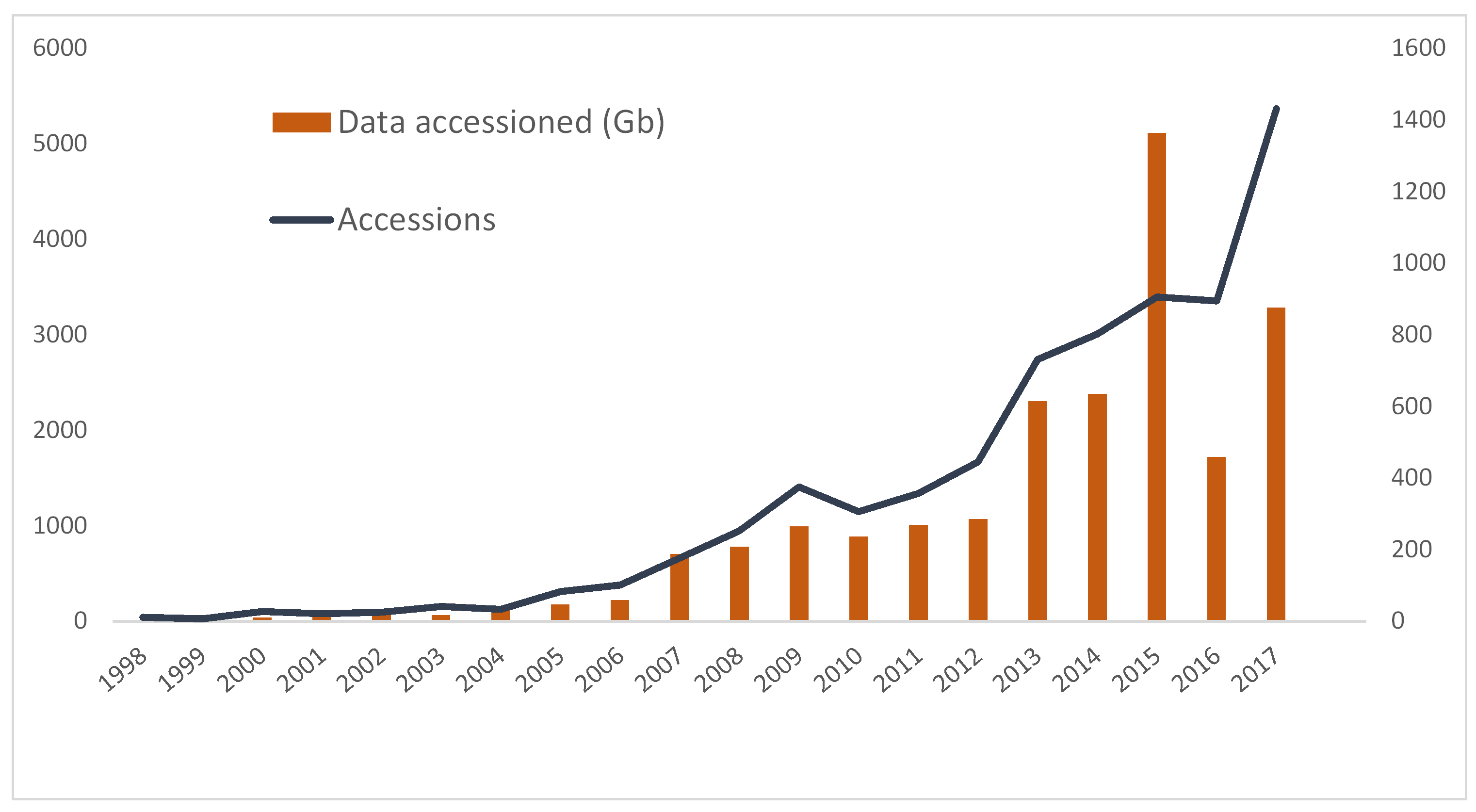
As the graph above shows, over the years we’ve seen an ever increasing number of Accessions, that is the single act of giving us a batch of files for archiving (note: many collections contain more than one accession). Despite a noticeable dip in 2016, the trend has clearly been for people to give us more stuff, and for the combined size of this to increase. A notable statistic is that we’ve accessioned over 15 Tb in the last 5 years. In total last year (2017), we received just over 3 Terrabytes of data, courtesy of over 1400 individual events; compared with 2007 (a year after I started work here) where we received c. 700Mb in 176 events. That’s an increase of 364% and 713% respectively over 10 years, and it’s interesting to note the disparity between those two values which I’ll talk about later. However at this point the clear message is that we’re working harder than ever in terms of throughput, both in number and size.
Is this to do with the type of Accessions we’re dealing with? Over the years our Collections Policy has changed to reflect a much wider appreciation of data, and community. A breakdown of the Accessions by broad type adds more detail to the picture:
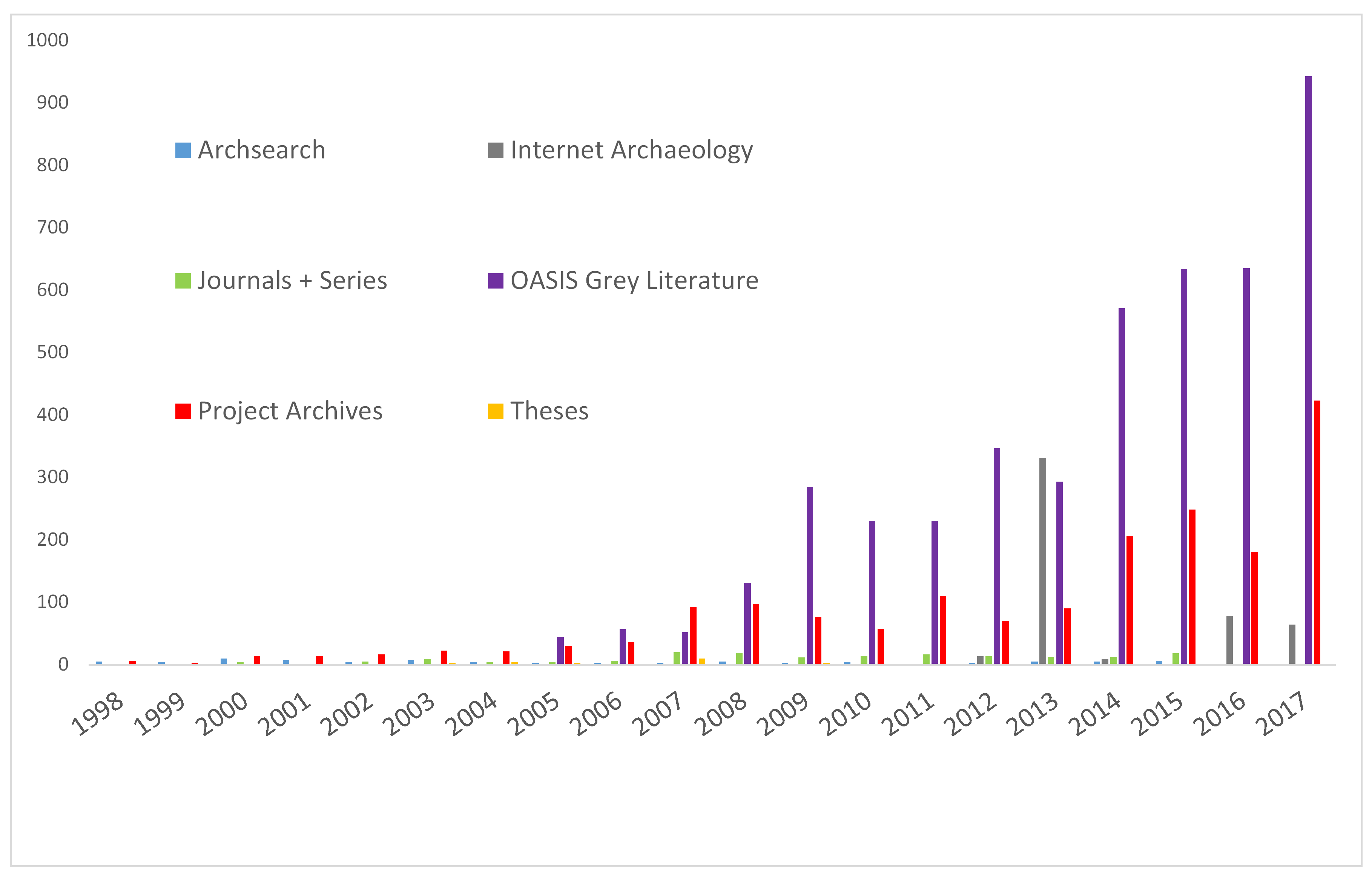
Aside from showing an interesting (to me at least) historical change in what the ADS takes (the years 1998-2004 are really a few academic research archives and inventory loads for Archsearch), this data also shows how we’ve had to handle the explosion of ‘grey literature’ coming from the OASIS system, and a marked increase in the amount of Project Archives since we started taking more development-led work around 2014. The number of Project Archives should however come with a caveat, as in recent years these have been inflated by a number of ‘backlog’ type projects that have included alot of individual accessions under one much larger project, for example:
- ALSF
- Ipswich, see https://doi.org/10.5284/1034376
- Exeter, see https://doi.org/10.5284/1035173
- BUFAU
- CTRL (although more of an internal re-organisation by Ray of how we were storing this project), see https://doi.org/10.5284/1000230
This isn’t to entirely discount these, just that they could be viewed as exceptional to the main flow of archives coming in through research and development-led work. So without these, the number of archives looks like:
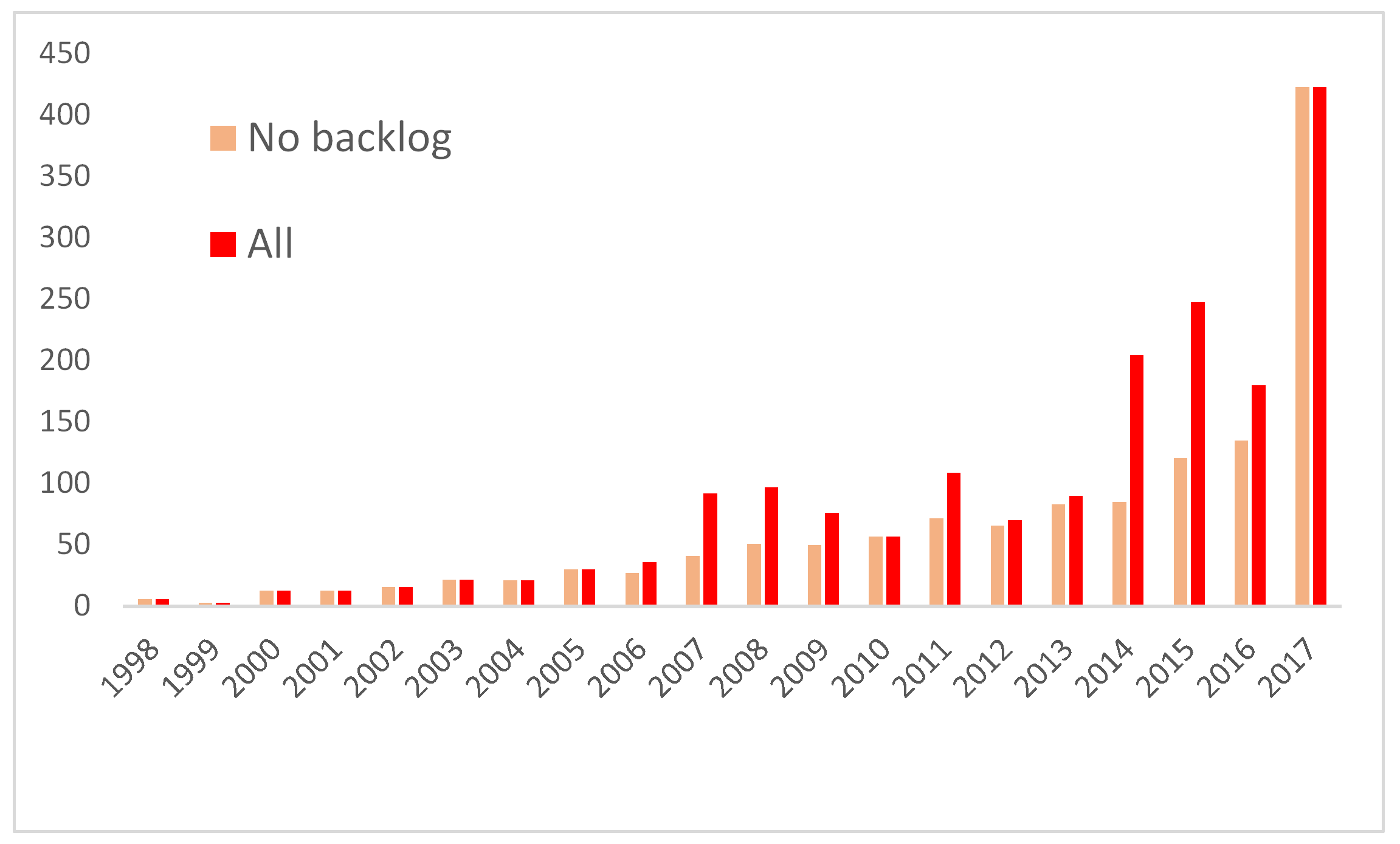
So, we can see the ALSF was having an impact 2006-011, and that 2014-2016 Jenny’s work on Ipswich and Exeter, and Ray’s reorganisation of CTRL was inflating the figures somewhat. What is genuinely startling, is that in 2017 this ceases to be the case, we really are taking 400+ ‘live’ Accessions from Project Archives now. How are these getting sent to us? Time for another graph!
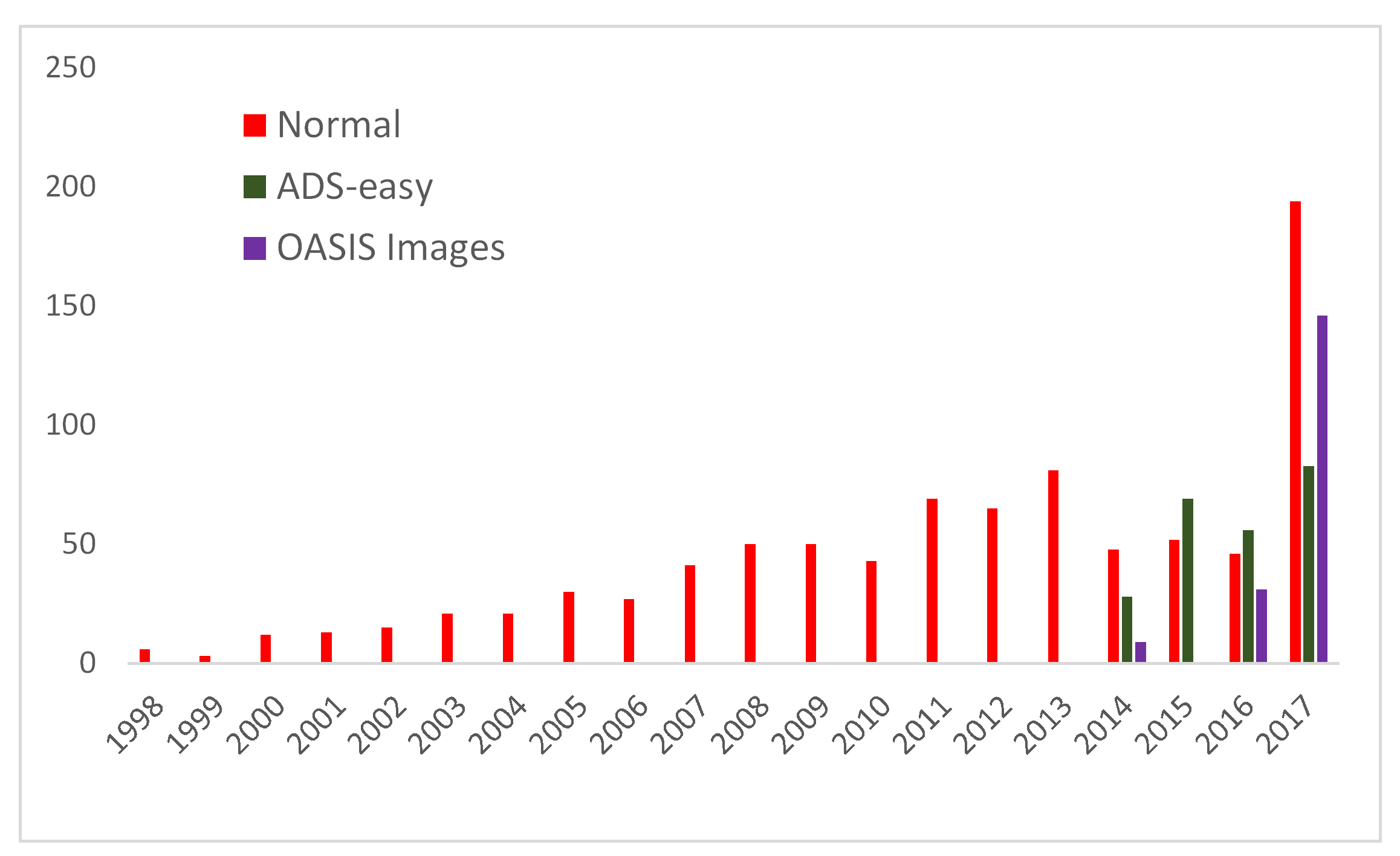
The numbers clearly show that post-2014 we are seeing alot more smaller archives being delivered semi-automatically via ADS-easy (limit of 300 files) and OASIS images (currently limited to 150 raster images). When I originally ran this query back in early 2017 it looked like ‘Normal’ deposits (*not that there’s anything that we could really call normal, a study of that is yet more blogs and graphs!) were dropping off, but 2017 has blown this hypothesis out of the water. What’s behind this, undoubtedly the influence of Crossrail which has seen nearly 30 Accessions, but also HLCs, ACCORD, big research projects, and alot of development-led work sent on physical media or via FTP sites (so perhaps bigger or more complex than could be handled by ADS-easy). Put simply, we really are getting alot more stuff!
There is one final thing I want to ask myself before signing off; how is this increase in Accessions affecting size? We’ve seen that total size is increasing (3 Tb accessioned in 2017), but is this just a few big archives distorting the picture? Cue final graphs…
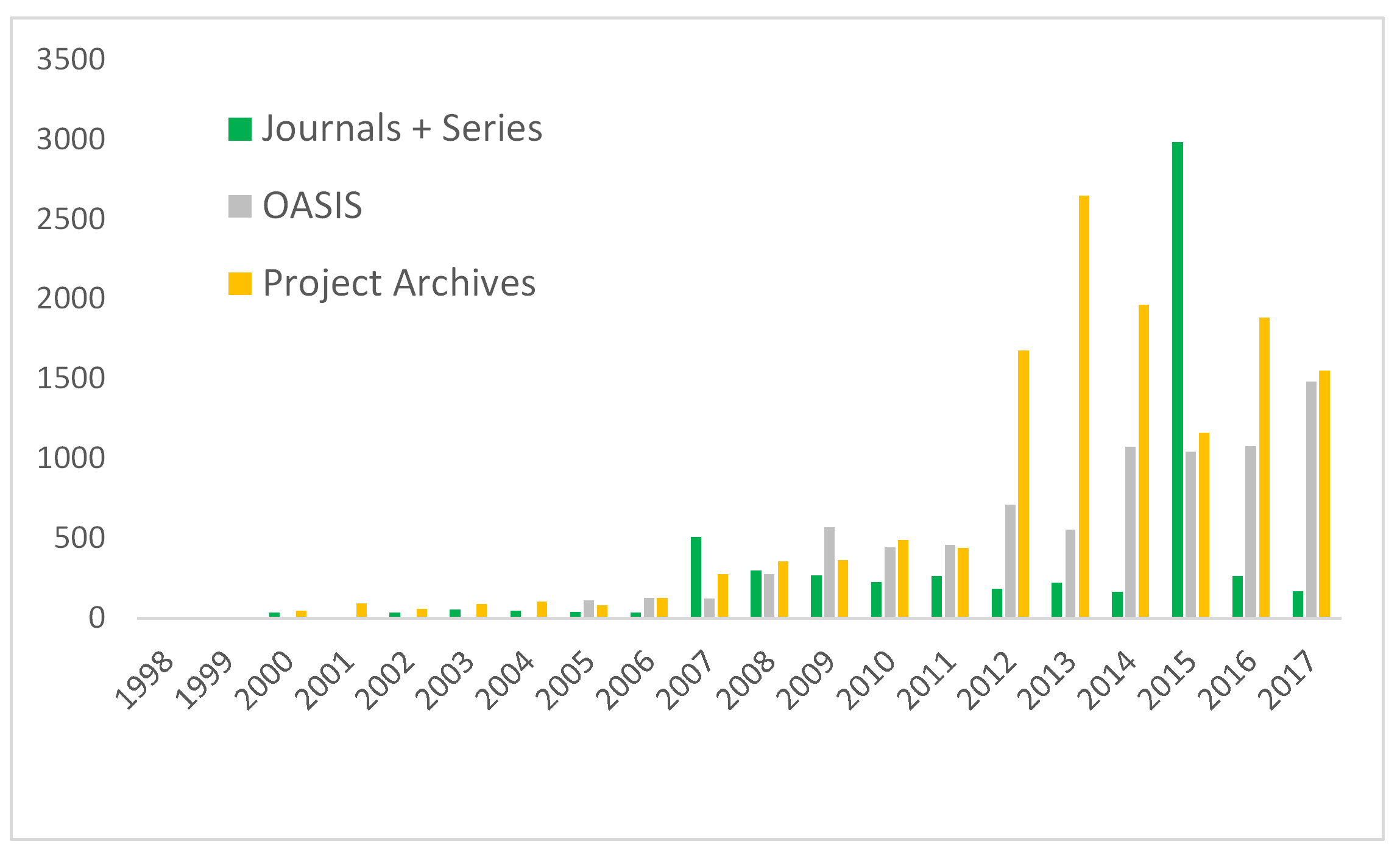
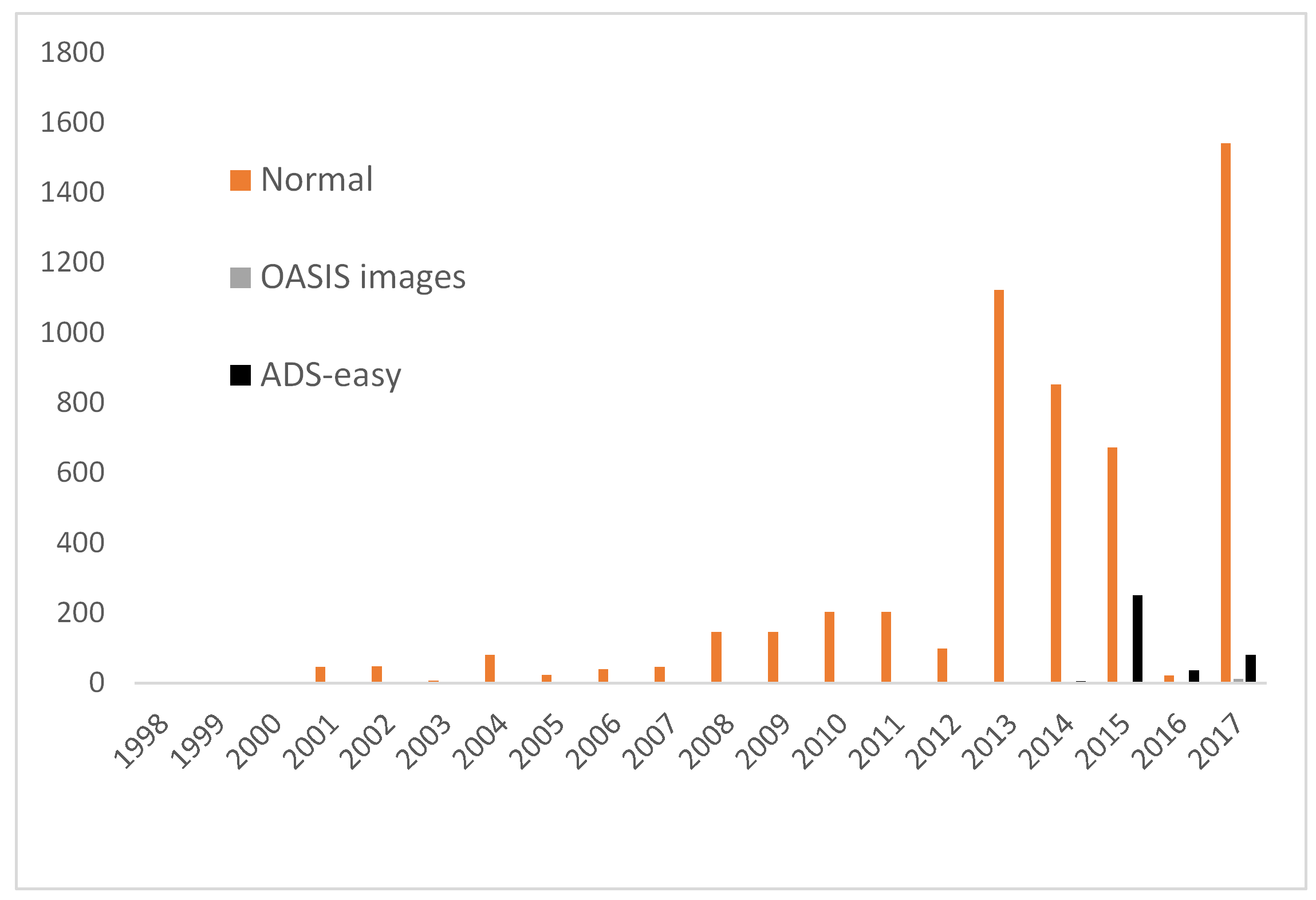
I’m surprised somewhat by the first graph, as I hadn’t expected the OASIS Grey Literature to be so high (1.5 Tb), although anecdotes from Jenny and Leontien attest to size of files increasing as processing packages enable more content to be embedded (another blog to model this?). Aside from this, although the impact of large deposits of Journals scans (uncompressed tiff) can be seen in most years, particularly 2015, it does seem as though we’re averaging around 1.5 Tb per year for archives. Remember, this is just what we’re being given and before any normalisation for our AIP (what we rely on for migration) and DIP (what we disseminate on the website). And, interestingly enough, the large amount of work we are getting through ADS-easy and OASIS images isn’t having a massive size impact, just under 400Gb combined for the last 3 years of these figure.
—————-
Final thoughts. First off, I’m going to need another blog or two (and more time at airports!) to go deeper into these figures, as I do want to look at average sizes of files according to type, and the impact of our preservation strategy on the size of what we store. However, I’m happy at this stage to reach the following conclusions:
- Over the last 5 years we’ve Accessioned 15 Tb of data.
- Even discounting singluar backlog/rescue projects and big deposits journal scans, this does seem to represent a longer term trend in growth
- OASIS reports account for a significant proportion of this amount: at over a Tb a year
- ADS-easy and OASIS images are having a big impact on how many Accessions we’re getting, but not an equal impact on size.
- After threatening to fall away, non-automated archives are back! And these account for at least 1.5Tb per year, even disregarding anomalies.
Right, I’ll finish there. If anyone has read this far, I’m amazed, but thanks!
Tim
ps. Still here? Want to see another graph? I’ve got lots…
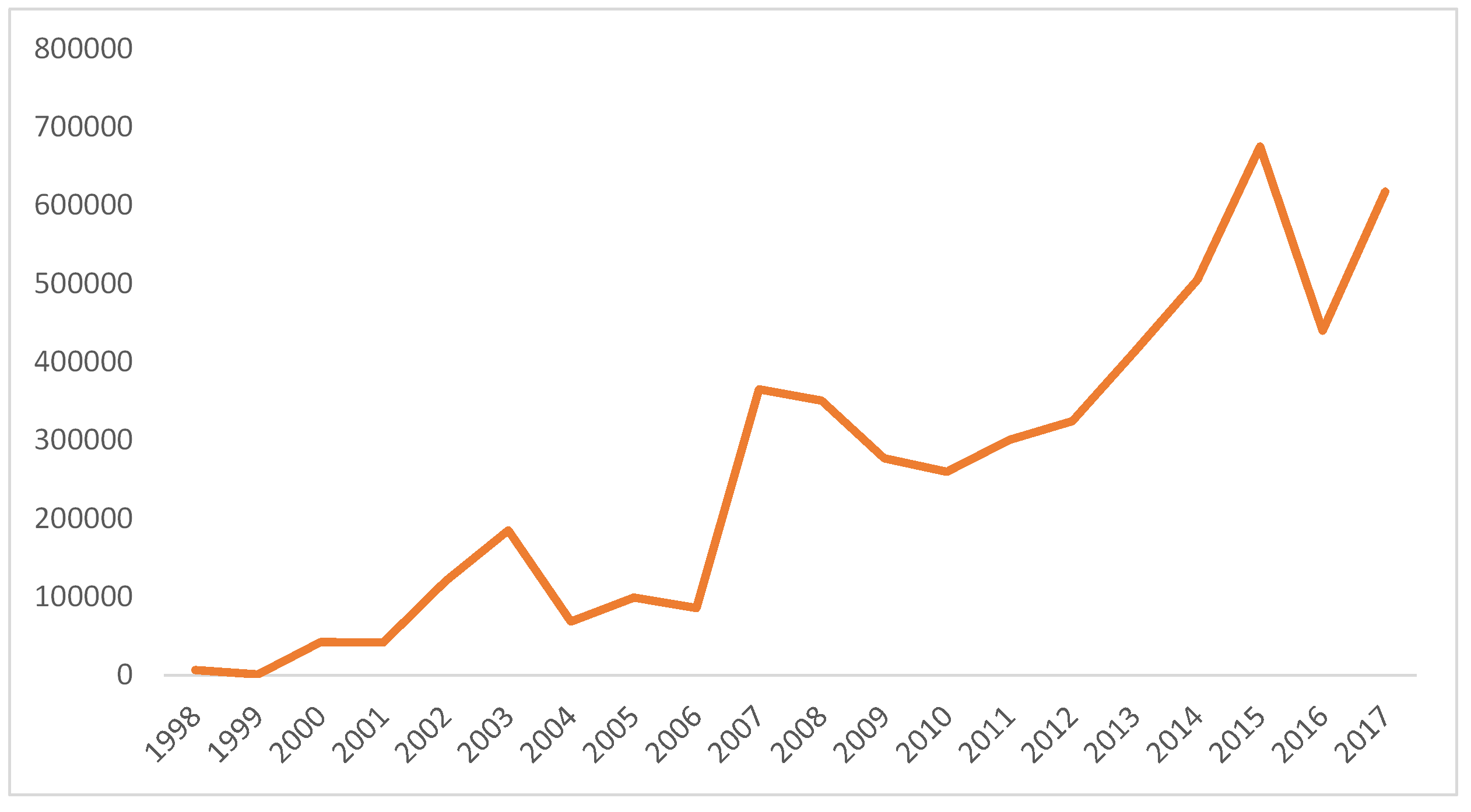


Looking forward to your future post on cloud-based solutions vs traditional physical storage space. You are not storing data protected by the GDPR so that’s one less headache.
Thanks Sonia! My colleague (Katie Green) has just spent alot of effort ensuring we’re in line with GDPR, but as you say the vast majority of our archives – thankfully – aren’t affected by this. Tim
Interesting stuff Tim.
Thanks David!