

This is the first of a two-part blog reporting on the progress of my work in preparing the digital data from the English Heritage Silbury Hill Conservation Project for deposition. For an introduction to my work, please see the ADS Spring 2013 newsletter
A bit of background
Silbury Hill is “the largest man-made mound in Europe” (English Heritage) roughly 4,500 years old and a mystery that many antiquarians and archaeologists have, in their time, tried to solve through extensive survey and excavation.
To summarise: The Silbury Hill Conservation Project began after a hole appeared on the summit in May 2000, after which the hill continued to be monitored through a series of surveys, assessments and evaluations. These proved that the hill was suffering from various collapses caused by previous excavations being inadequately backfilled and voids were therefore created by the subsidence of material.
The Silbury Hill digital archive: a monumental task
As mentioned in the ADS newsletter, the digital data generated from the Silbury Hill

Conservation Project represents all of the site visits, surveys, evaluations, excavations, photogrammetric recording, finds retrieval and environmental sampling undertaken over the span of 9 years as well as the consequent research, assessment and analysis of the site data.
At the beginning of 2012, the dataset comprised over 30,000 files and I was employed by English Heritage for three months to undertake the daunting task of selecting which files should be retained and renaming and reformatting files where appropriate. As it transpired, that three month period was not enough to even sort through which files needed to be kept for archiving and which should be discarded; consequently I was employed for a further year to continue to prepare the digital data for deposition.
A year! What’s taking so long?

The number of different phases of work created by a number of different team members over many years is one of the main contributing factors to the digital data becoming, shall we say, a tad chaotic. Over the course of the project, there were many staff changes and a large number of the team members from the 2007 excavations, which included temporary site staff, are no longer working for English Heritage.
Perhaps for this reason, there was no one person responsible for the management of the Silbury digital data as it was created, worked upon and stored in a dedicated project folder. Though a ‘Digital Archiving Strategy’ is mentioned in the archaeological project designs, as far as I can see from the documents in the archive, this strategy was not seen by the site team, nor was the management of digital data considered for the assessment phases; there is no mention of the creation or management of digital data in the project designs for the assessment of finds, environmental artefacts or the creation of illustrations and graphics, for example. There was no explicit strategy for dealing with the data, no naming conventions for the files, and the initial structure of the folder directories soon became disorganised through years of different people, creating files, copying files, working on copies of files or editing original versions. In the majority of cases this occurred without any process of selection or any working copies or draft versions being deleted and without any documentation being created, leaving no trail to follow to describe what had been done or why.
The archiving process was seen very much as something that needed to happen at the end of the project.
Step by step
Data selection/retention:
The first stage, for me, was to sort through the files to select which to keep for the archive and which to discard. This was a very long process made difficult by the fact that there was no coherent structure or descriptive naming convention. This meant that, in order to know what a file contained, why it was created and therefore how useful it may be, I sometimes had no clues from either its placing in the archive or its title. I therefore had to open every file, examine its contents so I could either assess its usefulness myself or seek further advice, which required me to try and work out when it was created and by who, then find out if the relevant staff member was still working for English Heritage. If the original creator was no longer available, the opinions of their colleagues and of the Project Manager had to be sought before a decision was made. I was in a fortunate position in that I was still in contact with some of my fellow site members from 2007 who had left English Heritage and so was able to pick their brains as well.
So far in the post-excavation process much of the data selection was on a case-by-case basis

using criteria based on the possible re-use of the files, keeping the archive consistent, removing sensitive information and basic common sense, for further guidance on selection and retention see the Archaeology Data Service/Digital Antiquity Guides to Good Practice.
In sorting through the archive it was mostly the lack of documentation that proved the biggest obstacle. As one of the site team members from the 2007 Silbury excavations I could slowly piece together a fair amount of the site data, but was completely in the dark when it came to either the more technical aspects of the archive or the files that had been created for personal use. So, much as the Silbury tunnels progressed metre by metre hampered by collapses along the way, I worked through the archive file by file, overcoming the various obstacles created by an untended dataset.
The final archive is half the size of the dataset I was originally faced with. It may be the case that potentially useful files have been discarded, it is more likely the case that there are files left in the archive that are superfluous, as many files have been kept out of a desire to be consistent or because they are referenced elsewhere. The site photographs are a good example of this, there are probably many that are not useful at all, but because they were not reviewed and discarded on site, they are tied into the primary site paper and digital records and therefore the later database, so they have been kept.
Data structuring:
As files were selected, they were renamed and relocated to a more structured directory. The digital archive had grown organically, for example although originally there was a dedicated ‘IMAGES’ folder, in the end images were scattered in various forms of primary data, working drafts and copied files in various folders, either moved or created by individuals for working purposes and never discarded or re-organised. As files were renamed and sorted into a logical folder structure it became clearer that there were more duplicates or working versions than my original sift had shown, as like files were more easily compared once grouped together and given a descriptive name. Throughout all of this process, each decision made and each file relocation also had to be documented in order that others and I would have a trail to follow should something need to be revisited later.
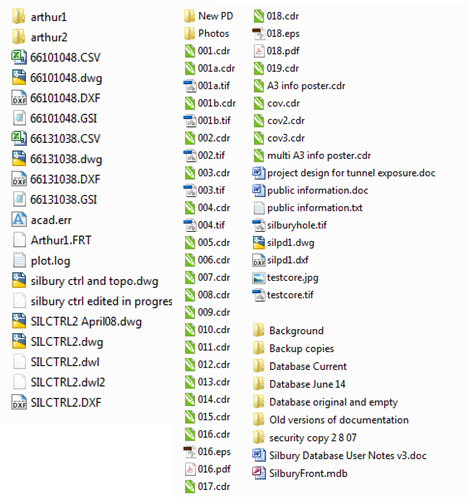
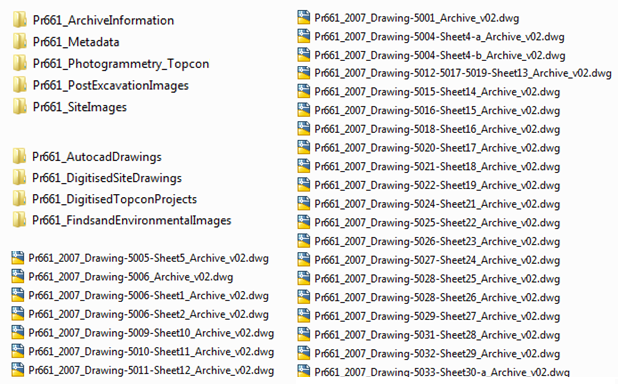
Documentation

Once the files had been selected, sorted and renamed, the documentation stage could begin. Again, I found that this process was made much more difficult given that some of the files had been created years ago by people who were now no longer working for English Heritage. Some of the information useful to repositories, such as the ADS, was no longer available and where I couldn’t find or create the information necessary for useful metadata myself, I had to turn to colleagues or in some cases leave blank spaces.
When creating the metadata for the Silbury Hill digital archive, I used the ADS Guidelines for Depositors and the Guides to Good Practice. The ADS provides templates to fill out and these seemed simple and intuitive, but still an onerous task when documenting 15,000 files with gaps in knowledge. Had I, as the person responsible for the site digital data by the end of the project or my predecessor, known this was required while still working on site, we could have dedicated a few minutes each day to completing this task. If this had been the case across the project, all processes of selecting and structuring the project data ready for archive would have taken much less time and therefore been much more cost-effective.
I have now completed the vast majority of the preparatory work: the files have been sorted, superfluous files have been removed from the archive, all of the files have been renamed, the archive now has a logical and consistent structure and all of the files relating to the photogrammetric recording and all of the images have been fully documented according to the Guidelines for Depositors and the Guides to Good Practice. It is intended that these files will be deposited with English Heritage Archives within the next couple of months, so as the title of this blog suggests there is indeed a light at the end of the tunnel!
What is the next step?
The rest of the dataset includes survey files, reports, project designs, geophysics data and databases. I will be documenting these files and they will be deposited with the ADS within the next few months, after which I will write a sequel to this blog relating any thoughts or issues arising from that section of work.
So, look out for the next thrilling instalment coming soon to an ADS blog screen near you!
For more information on preparing digital data throughout the project lifecycle, please see the Guides to Good Practice
For more information on the Silbury Hill conservation project, check out the Silbury-related reports on the Historic England Research Reports search page.
Jenny’s next instalment can be found in Silbury Hill: An Update



…Maybe you’ve come across the reason that Atkinson left all the papers from his 1960s Stonehenge etc.work stuck underneath his bed….
Perhaps, it does makes one think about all the other records that may be secreted away yearning to be archived.
Sympathy! And it sounds like a great job to date…
Many thanks! It’s been a marathon, but it’s nice to see the final stages of a project I’ve been involved with, a new perspective for me.
I’ve been keeping an eye on Silbury itself; much to our amazement it is still standing…
Amazing! Cannot believe the process that you have been through. Good luck with the next stage!