With the SENESCHAL project finally wrapped up, we thought it would be good to do a final post on how we implemented the SENESCHAL vocabularies into our systems. This follows on from my previous post, SENESCHAL Vocabularies: value to the ADS, which gives more background into the project in general. That post also lays out the original vision and a mock-up for the integration of the SENESCHAL vocabularies into our Collections Management System (CMS), which we can now safely say has been fully realised.
CMS
The CMS integration was the primary objective for the ADS within the SENESCHAL project, as it would have the biggest and most immediate impact. We wanted a simple way to accurately align our archive metadata to the official vocabularies used within Britain. This not only helps us manage our archives better, it also ensures our users can discover our archives in a more consistent and accurate manner. Before the SENESCHAL project, our “alignment” with the Monuments Thesaurus was done via a free text field. Even with the extreme fastidiousness of our digital archivists, errors had the potential to creep in. Entering data this way also uncoupled the term from its related concepts and hierarchy when recorded within our CMS. This could be recreated, but the onus was put on the user (us in most cases, but also the users of the archive) of the data to manually “realign” the term.
The final implementation actually closely followed our original vision, which was to tightly integrate lookups to the SENESCHAL vocabularies from the CMS Coverage interface. This is where the previous free text entries were done, so existing workflows did not need to be radically altered to accommodate the lookups. The following animation illustrates how a digital archivist uses the CMS to align an archive with the SENESCHAL vocabularies.
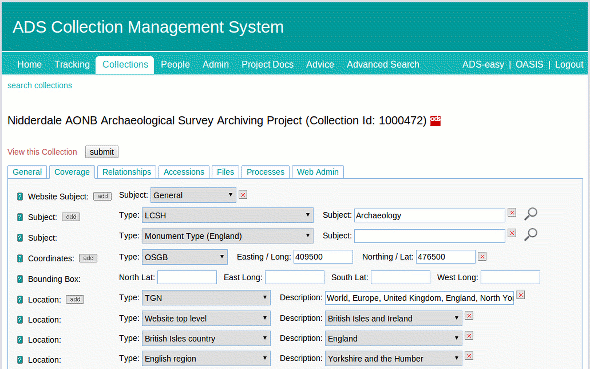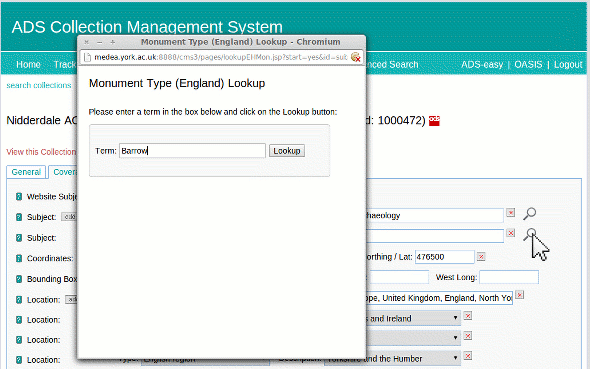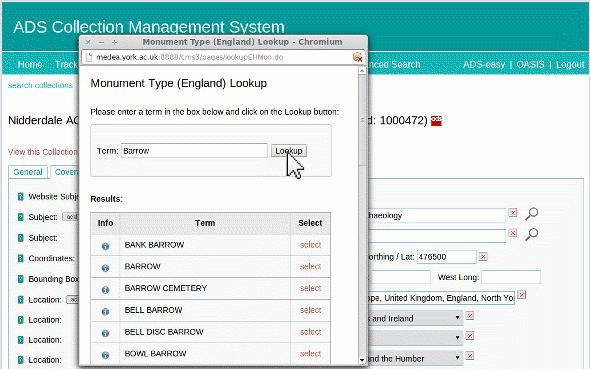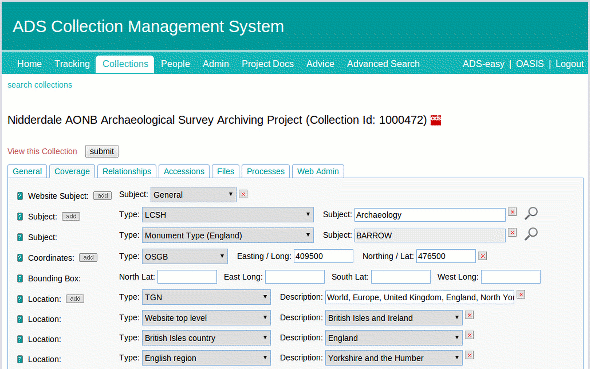
When a Subject “Type” is selected that has a vocabulary lookup, a search icon appears next to the text field. Clicking on that opens up a lookup window, which allows the archivist to type in a value to lookup against the SENESCHAL RESTful service. The results are displayed along with an information link to get more information on that concept if necessary. Once the correct concept has been identified the archivist can select the term and it is inserted (along with its URI) into the CMS database. We plan on improving the integration in the future by enabling the concepts skos:scopeNote value to be displayed when the mouse is hovering over the term in the results list.
FISH Toolkit
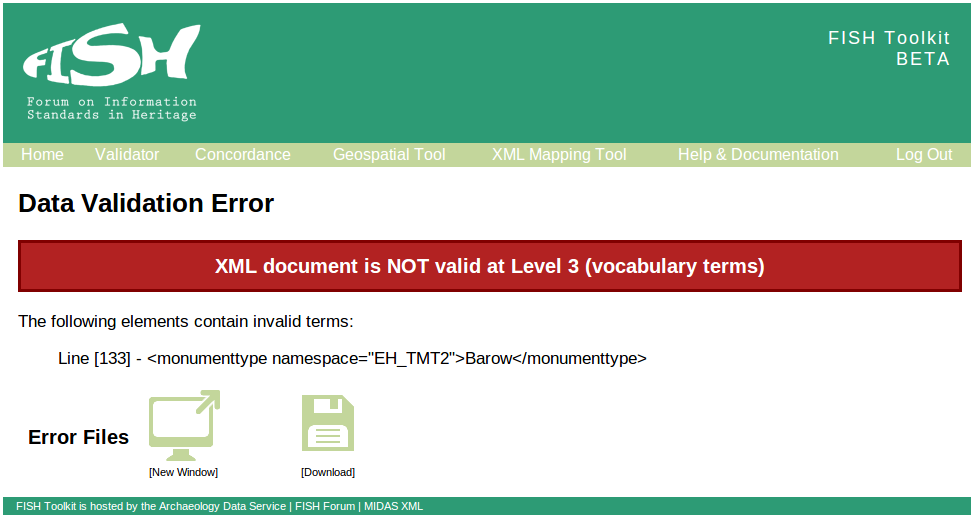
Reusing the code we wrote for the CMS integration, we were able to easily apply the SENESCHAL lookups to the FISH Toolkit to provide better validation. The original Data Validation Tool only allowed users to validate their MIDAS XML against the MIDAS XSD and that level 2 mandatory elements were included. With the SENESCHAL lookups we could now also begin to validate whether the values for monuments, objects or events in the XML document were valid terms within their respective vocabulary. This kind of feature was a priority in the initial FISH Toolkit specification, but was unattainable until something like the SENESCHAL project came along.
ADS-easy & OASIS
We also intend on reusing the SENESCHAL lookups and interfaces within other ADS systems where appropriate. The two most obvious candidates are ADS-easy and the next incarnation of OASIS. ADS-easy integration would be similar to the CMS implementation, which would allow users to easily search and align their data with SENESCHAL vocabularies. Since the next incarnation of OASIS is only in the early stages, its hard to anticipate how the interface will look and feel. There will certainly be a need to align records with vocabularies, so it is probably a safe bet to say that OASIS integration will also be similar to CMS.
As mentioned before, the benefit of the SENESCHAL lookups to ADS projects is two-fold. On one hand it enables a simple mechanism for aligning our metadata against formal vocabularies, and on the other it makes that metadata more interoperable from a re-use perspective.
Source Code
The code used to do the SENESCHAL lookups is part of a larger library used within the ADS, called the Linked Data Toolkit. This Java code has been written to simplify the process of performing lookups to various Linked Open Data vocabulary and thesauri providers, such as the Library of Congress, the Ordnance Survey, GeoNames, DBpedia and the SENESCHAL project. The toolkit provides programmatic ways to get precise or fuzzy results from RESTful web services and SPARQL endpoints. The code is all available via GitHub, and people are welcome to take it, fix it, improve it and re-use it in their own Java projects. The documentation is thin at the moment, but I do intend on filling it out to help others make sense of it. I will also try to create a Command Line Interface to the toolkit to allow basic interaction with the lookups from any workstation with Java.


