Here it is, my Day of Archaeology 2013 and after a routine check of my emails and the daily news I’m ready to begin!
I am currently approaching the end of a year-long contract as a Digital Archivist at the Archaeology Data Service in York on an EH-funded project to prepare the Silbury Hill digital archive for deposition.
For a summary of the project, see the Collections Highlights section of the ADS newsletter and for a more in-depth account of my work so far check out my blog from a couple of weeks ago: “The Silbury Hill Archive: the light at the end of the tunnel”

Very briefly, though, my work has involved sifting through the digital data to retain only the information which is useful for the future, discarding duplicates or superfluous data; sorting the archive into a coherent structure and documenting every step of the process.
The data will be deposited with two archives: the images and graphics will go to English Heritage and the more technical data will be deposited with the ADS and as the English Heritage portion of the archive has been completed it is time for the more technical stuff!
So, the plan for today is to continue with the work I have been doing for the past few days: sorting through the Silbury Hill database (created in Microsoft Access).
Originally, I had thought that the database would just need to be documented, but, like the rest of the archive, it seems to have grown fairly organically; though the overall structure seems sound it needs a bit of work to make it as functional as possible and therefore as useful as possible.
The main issue with the database is that there are a fair amount of gaps in the data tables; the database seems to have been set up as a standard template with tables for site photography, contexts, drawings, samples, skeletal remains and artifact data etc. but some of these tables have not been populated and some are not relevant. The site photography and drawing records have not been entered for example, meaning that any links from or to these tables would be worthless. The missing data for the 2007 works are present in the archive, they are just in separate Excel spreadsheets and there are also 2001 data files, these are in simple text format as the information was downloaded as text reports from English Heritage’s old archaeological database DELILAH. The data has since been exported into Excel, so, again to make the information more accessible, I’m adding the 2001 data to the 2007 database.
My work today, therefore, as it has been for the past couple of days, is to populate the empty database tables with the information from these spreadsheets and text files and resolve any errors or issues that cause the tables to lose their ‘referential integrity’, for example where a context number is referred to in one table but is missing from a linking table.
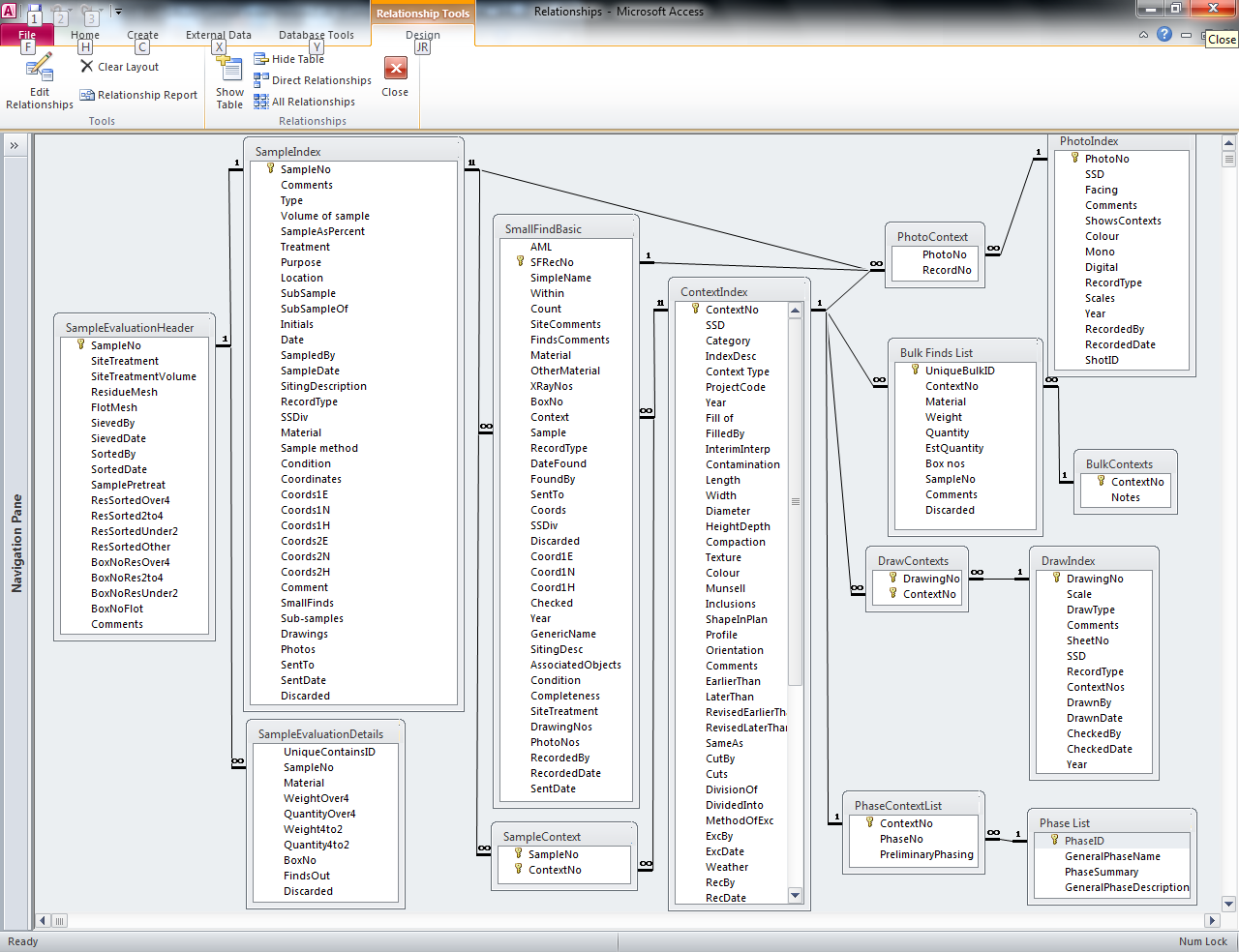
So, this morning I started with the 2001 drawing records. The entering of the data itself was fairly straightforward, just copying and pasting from the Excel spreadsheet into the Access tables, correcting spelling errors as I went. Some of the fields were controlled vocabulary fields, however, which meant going to the relevant glossary table and entering a new term in order for the site data to be entered as it was in the field.
Once the main drawing table was completed, the linking table needed to be populated; again, this was done fairly simply through cutting and pasting from Excel.
The next step was the most time-consuming: checking the links between the tables, to do this I went to the relationship diagram, clicked on the relevant link and ticked the box marked ‘enforce referential integrity’ this didn’t work which meant that a reference in one table was not matched in the linking table which meant going through the relevant fields and searching for entries that were not correct. The most common reason for these error messages was that an entry had been mis-typed in one of the tables.
That took me up to lunchtime, so what about the afternoon? More of the same: starting work on the sample records with the odd break for tea or a walk outside to save my eyes!
As much as the process of updating the database has been fairly routine, it’s an interesting and valuable piece of work for me as it is the first time I’ve ever really delved into the structure of a database and looking at the logic behind its design. I was fortunate in that I had attended the Database Design and Implementation module taught by Jo Gilham as part of the York University Msc in Archaeological Information Systems which gave me a firm foundation for this work. Also very helpful was the help provided by Vicky Crosby from English Heritage who created the database and provided a lot of documentation in the first instance.
The next step once the data has been entered will be to remove any blank fields and tables and then to document the database using the ADS’ Guidelines for Depositors and then to move on to the survey data and reports.
I’m looking forward to seeing it all deposited and released to a wider world for, hopefully, extensive re-use and research!
This blog was originally posted as part of the Day of Archaeology 2013