ADS blog
Casting an eye on the new web templates for ADS Archives
As we announced back in March, the ADS is due to launch a series of new features for the ADS Archives templates that provide an accessible…
As we announced back in March, the ADS is due to launch a series of new features for the ADS Archives templates that provide an accessible…

Towards the end of 2023 the ADS Library passed a considerable milestone of 80,000 fieldwork reports. This corpus is now one of the largest collections of…

This year’s CAAUK conference, organised by the British chapter of CAA (Computer Application & Quantitative Methods in Archaeology), was held in Edinburgh on Friday 24th and…
The work of the ADS is overseen by a Management Committee made up of representatives of key stakeholders, funders, and user communities. The Committee meets once…

Those of you who have visited the ADS offices will know we are very fortunate to be part of the Department of Archaeology at the University…
Editor Intro: This week’s blog post is written by Richard Paxford, an ADS digital archives assistant who recently joined us in York. Below Richard writes about…

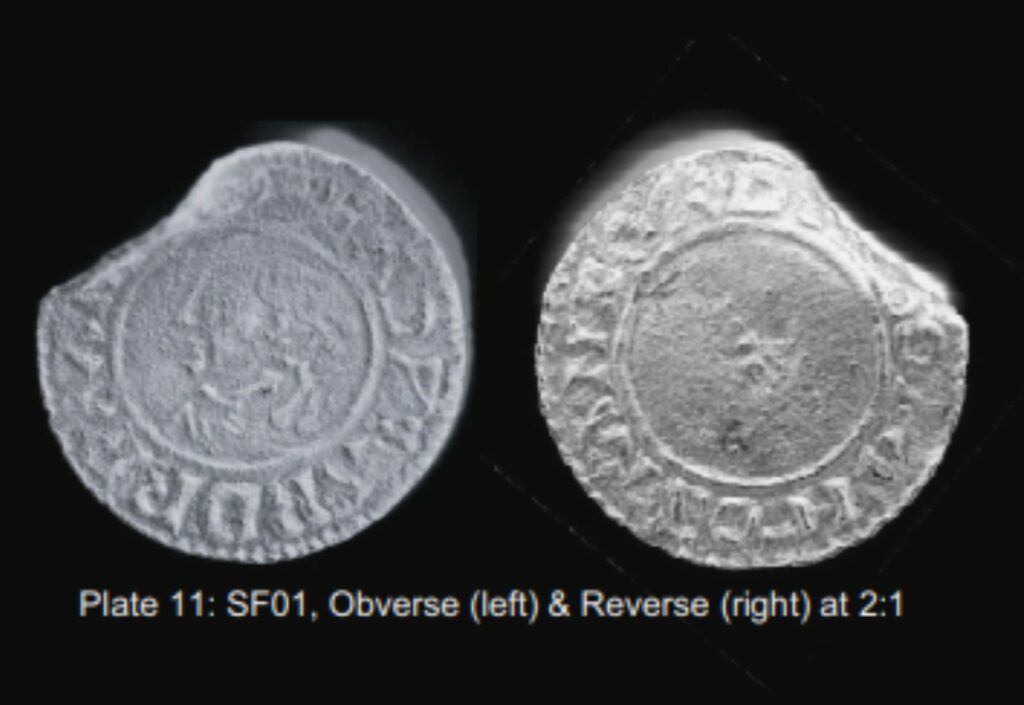
High Speed Two’s groundbreaking archaeology programme is currently not just Europe’s largest excavation but also a treasure trove of insights into the lives that shaped modern…

Editor Intro: This week’s blog post is written by Marco Brunello, an ADS Digital Archives Assistant who recently joined us in York. Below Marco talks about…

Last month, our team of archivists were busy with another ‘Archives Sprint’, a week dedicated to processing digital archives deposited through our website’s ADS-easy interface. Over…

Today I’m in Belfast talking at the 2023 Annual Conference of the Archives & Records Association. For those who can’t make it, or were so taken…

The Council for British Archaeology’s Festival of Archaeology launched this year on the 15th July. In celebration of this event, we at the ADS and Internet…