
Planning for the creation of digital data
From the moment a project begins, careful thought must go into the planning of the digital materials that will be created throughout the project’s lifecycle. Basic planning at the beginning of the process will significantly simplify the submission of project materials to a digital archive and the creation of an archive. Initial planning also will help ensure data security and recovery throughout the lifecycle of the project. Whether one is creating an archive or contributing to an existing repository, it is critical to prepare ahead of time. Specific issues to consider include: file naming, formats, versioning, as well as storage, backup strategies, and documentation. This section contains more detailed discussions of all of these issues.
Before planning, decide exactly how to archive materials:
- If a new digital repository will be created, review the sections of these Guides on digital archiving, and consider how to approach each of the issues presented. Archive creators also need to address requirements of access and preservation in perpetuity.
- If materials will be contributed to an existing repository, contact that repository during the planning stage of the project to review the issues described in this section. This will be helpful in selecting the appropriate repository for data and simplify the submission process.
Issues to consider while planning a project:
While project planning is often specific to the project and data types being generated (and will be covered within the technique-specific chapters that follow), some general project planning principles apply regardless of project type.
- Planning for the creation of data (covered generally in this chapter) which includes:
- Preparing a project design that defines the types of digital data that will be created or acquired, and defines and documents areas of responsibility for creating and managing these files at all stages of life.
- Selecting the file formats that will be used during the data creation and analysis phases, and how these relate to formats used in the secure archiving and dissemination of data. The formats used may be the same or may change throughout the project lifecycle.
- Assessing the level of documentation and metadata required at the various levels (project, technique, file) to ensure that the project and its datasets are understandable and reusable. This is covered in the following chapters on Project Documentation and Project Metadata.
- Choosing how to archive:
- Assessing the type of digital archive that will be created and deciding which files will be preserved. This is covered in the following chapters on Data Selection and Storage.
- Contacting the digital archive facility destined to receive the files to see which specific guidelines or standards should be followed. If guidelines are not specified, it is recommended that the advice in these Guidelines is followed.
Most importantly, data creators need to include in their project plans, at the outset, the tasks necessary for the successful completion of the project. Throughout the life of the project, the plans for these activities should be reviewed and modified as necessary. This section outlines some of the considerations required at a general project level during the planning and data creation stages.
Data creation and capture
Distinctions should be made early on in a project between data that is created digitally (“born digital”) and that which is captured from a non-digital original (digitised). Within each of the data type or technique-based chapters in these Guides, file formats and software applications commonly used during the data creation phase are discussed in terms of their suitability for long-term preservation and possible migration paths to other formats. There are a number of general principles, commonly cited by archives and repositories (see Todd 2009), that guide the identification of stable and reliable file formats.
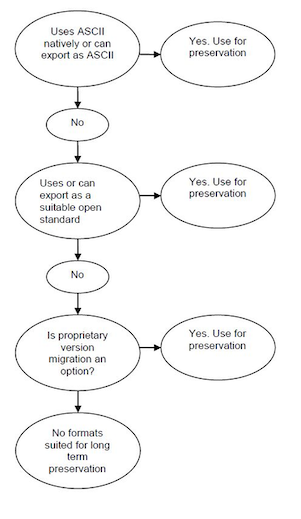
- Open and proprietary formats and standards – There is a general preference among archives and repositories to store data in formats which are standardised, openly documented and, where possible, non-proprietary. Such formats are considered to be more easily sustainable due to the openness and availability of the file format and, in many cases, its use across platforms or by multiple applications. This is discussed elsewhere (Library of Congress[1] and Todd (2009)) in terms of disclosure, external dependencies, impact of patents and adoption.
- Binary and plain text files – For many datasets, such as raster images, file formats based on binary encoding are the only options. However, for a wide range of datasets, such as spreadsheets, databases, text documents and so on, there is generally an option (and, archivally, a preference) to use a file format based on textual encoding (e.g., ASCII plain text or XML). The advantages of this preference are that the file format is more transparent (i.e. it is human-readable and more open to direct analysis) and, as a result, more likely to be identified in terms of content and associated software. Easy access to file content also means that such formats have fewer external dependencies and more possible migration paths should the associated software become unavailable.
- Compressed files – Compression can be used either in the creation of a compressed archive file (e.g., a ZIP or RAR archive) or within specific file formats such as JPG or PNG. In both cases, it can use either lossless (no data is discarded) or lossy techniques. In the case of single “archive” files, as with binary encoding, data compression creates a potential barrier to identifying file types and accessing content. When combined with security features such as password protection, such encoding can ultimately make data permanently inaccessible. Compression used within a file format, such as JPG images or MPEG video, can cause additional problems and degradation of data quality – known as “generation loss” – when files are continuously reprocessed and recompressed. In all files in which it is used, compression can result in data loss when using lossy techniques, as well as magnify the effect of data loss or corruption via bit corruption (Heydegger 2008).
These sections recognise that, while certain formats may not be suitable for long-term preservation, such formats may be the most appropriate for data creation, development and dissemination (Brown 2008:5). It is recommended that such considerations be recognised in the data creation stage of a project so that adequate planning can be put in place—if required—for the later conversion of possibly problematic files.
An additional element that is key to identifying a suitable file format is the level of adoption that a specific file format has within a certain community. This can vary between techniques, data types and countries and so will be discussed in more detail with specific chapters later in these Guides.
There are a number of resources available that describe in detail the criteria used to identify suitable digital formats for preservation. Examples include those published by the Library of Congress,[2] the UK Nation Archives (Brown 2008) and the Digital Preservation Coalition (DPC)[3].
Digitised data
These Guides largely address born-digital data and do not aim to provide advice on digitisation. However, such projects, whether digitising internally or outsourcing such work, should still consider the implications of file formats upon the resulting dataset. Regardless of format, such projects should plan to digitise original material using the highest quality data capture to create archival-quality data files. These files may be compressed for dissemination purposes by techniques that often depend on degrading data quality, and it may be advisable to create and store multiple versions of each file for different purposes. The originals from which the digital data were created may still be useful, and a documentary archive should be consulted to establish whether this information should be preserved in physical form.
A number of organisations and guidelines exist which provide substantial guidance on undertaking digitisation. JISC Digital Media provides a wide range of advice on digitising existing images as well as analogue audio and video. Other guidelines, such as those produced by the AHDS and UKOLN,[6] provide shorter guidance on digitisation project planning.
Licensed and external data
Licensed and external data provide unique challenges to digital archiving as copyright, licenses, or software may prohibit some archival tasks. Challenges may include the ability to copy, reproduce, or convert files from their formats into the archive, or the ability to contribute those files to the archive. The latter may specifically be challenging, for example with a GIS file where the underlying map layer is licensed and its removal will significantly diminish the ability to interpret, read, or use the file later.
File naming conventions
Regardless of the source of the data, one of the first (and most immediate) ways of ensuring that data is understandable is to use meaningful file names that reflect content. Data creators should plan to use standard file naming conventions and directory structures from the beginning of a project and, where possible, use consistent conventions across all projects. Directory structures and file names are discussed in relation to specific types of data in a number of the following chapters, but general principles and conventions to consider are:
- Reserve the 3- or 4-letter file extension for application-specific codes, e.g. PDF, DOCX, TIF, and avoid using a full stop/period (.) elsewhere in a file name.
- Where possible, avoid using spaces within filenames, as they can cause problems in some operating systems. It is recommended that data creators use the underscore character (_) to imply a space within the filename.
- Include some means of identifying the relevant activity in the file name, e.g., a unique reference number, project number or project name.
- Include version number information in the file name where necessary.
Files generated under certain operating systems may have specific requirements, e.g., DOS must use standard 8-character file names with 3-character file extensions, whereas long file names may be used under a Windows environment.
Version control
It is extremely important to maintain strict version control when working with files, especially if different people are working on single files or if files undergo multiple stages of processing. For example, the Newham Museum Archaeological Services archive (see What is Digital Archiving? for more details) contained multiple versions of the same file without any indication of which was the most current. As the archive had no documentation to accompany the digital files, the ADS was forced into making judgments on the currency of the files based on their date and file size.
There are three common strategies for providing version control:
- File naming conventions
- Standard headers listing creation dates and version numbers
- File logs
It is important to record, where practical, every change to a file no matter how small the change. Versions that are no longer needed should be removed after ensuring that adequate backup files have been created.
File structures
Digital files should also be organised into easily understandable directory structures. It may be desirable to collect related data files in a folder using standard naming conventions to aid retrieval from the directory structure. Some files produced as the result of certain techniques (e.g., geophysical survey or GIS) are best structured and stored in standardised file structures and these are discussed in the relevant chapters later on in these Guides.
Storing digital data – precautions during the data creation stage (and beyond)
During the working life of most projects, digital data will be created on the hard disks of standalone PCs, on laptop computers or on network drives. Additionally, data may be acquired or stored on USB drives, backup tapes, CD or DVD ROMs or other electronic media. Ideally, however they were created or acquired, digital files in current use will be routinely backed up as part of good working practice.
It is not sufficient to leave digital media languishing on shelves or in data safes. Fireproof, anti-magnetic facilities are extremely important for the safe storage of digital media, and backup versions should be stored separated from original media. Data creators should ensure that the archive is complete and that documentation is included before storing it away. It is also important to employ an effective data management system in which file storage locations and media labeling strategies are noted. Data creators can follow a number of simple procedures or strategies to ensure that data are safe during the creation phase of a project.
Secure backup
Backup is the familiar task of ensuring that there is an emergency copy, or snapshot, of data held somewhere other than the primary location. For a small project, this may mean a single file held on an external disc drive or over a network; for a larger project or dataset, it may mean more rigorous procedures of disaster planning, with fireproof cupboards, off-site copies and daily, weekly and monthly copy creation. These are important in the lifespan of the project, but are not the same as long-term archiving because once the project is completed and its digital archive safely deposited, the action of backing up will become unnecessary.
The most widely used backup strategy is the so-called “Grandparent-Parent-Child” strategy, often implemented by large institutions using digital tapes, but also appropriate to other storage media. The system works by employing a rotation of full and partial backups on each day of the week or month. The most recent full backup, the “Parent,” contains a snapshot of the whole network or dataset at the start of a week. “Children” are more frequent, normally daily, backups containing only the changes to the system executed on that day. These tapes don’t have to be kept in perpetuity, but can be recycled every time a new Parent is created. Once a month or so, a permanent and complete snapshot is taken, which should be stored in perpetuity and would not normally be recycled. This monthly backup is the “Grandparent” and can be relied upon in moments of real crisis. It is best practice that the weekly and monthly backups are stored offsite, preferably in a secure, fireproof, anti-magnetic environment. Of course, for a small or relatively static dataset, such regular copying is excessive. The system can be tailored to individual requirements and the time periods expanded or contracted as necessary.
It is also important to validate backup copies to ensure that all formatting and important data have been accurately preserved. Create backups when a project is complete or dormant, prior to any major changes, or if files are large enough to cause handling difficulties on the network. Each backup should be clearly labelled and its location should be logged.
Periodic checking for viruses and other issues
Periodic checks should be performed on a random sample of digital datasets, whether in active use or stored elsewhere. Appropriate checks include searching for viruses and routine screening procedures included in most computer operating systems. These periodic checks should be in addition to constant, rigorous virus searching on all files.
The creation of secure backup copies does not adequately protect digital data in the long term, whether from the degradation of the media on which they are stored or from changes in hardware or software leading to the data becoming irretrievable. Additional steps are required for successful digital archiving.
[1] http://www.digitalpreservation.gov/formats/sustain/sustain.shtml
[2] http://www.digitalpreservation.gov/formats/sustain/sustain.shtml
[3] https://www.dpconline.org/handbook/contents
[6] http://www.ukoln.ac.uk/interop-focus/gpg/DigitisationProcess/
Bibliography
Brown, A. (2008) Selecting File Formats for Long-Term Preservation. The National Archives.http://www.nationalarchives.gov.uk/documents/selecting-file-formats.pdf
Heydegger, V. (2008) ‘Analysing the Impact of File Formats on Data Integrity’ in Archiving 2008, Volume 5.
Todd, M. (2009) File Formats for Preservation. DPC Technology Watch Series Report 09-02. http://www.dpconline.org/publications/technology-watch-reports
‘Planning for the Creation of Digital Data’. Edited by Kieron Niven
Archaeology Data Service / Digital Antiquity (2011) Guides to Good Practice